
Since our initial release of auto-sklearn 0.0.1 in May 2016 and the publication of the NeurIPS paper “Efficient and Robust Automated Machine Learning” in 2015, we have spent a lot of time on maintaining, refactoring and improving code, but also on new research. Now, we’re finally ready to share the next version of our flagship AutoML system: Auto-Sklearn 2.0.
This new version is based on our experience from winning the second ChaLearn AutoML challenge@PAKDD’18 (see also the respective chapter in the AutoML book) and integrates improvements we thoroughly studied in our upcoming paper. Here are the main insights:
Improvement 0: Practical considerations
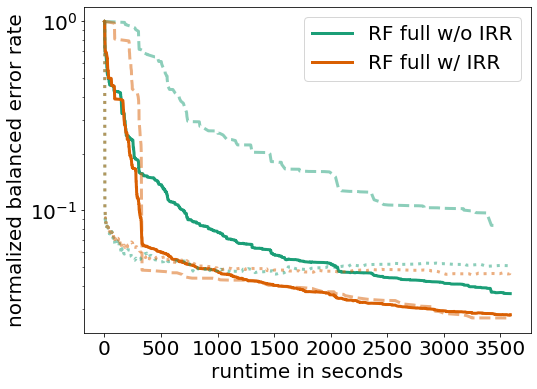
To increase efficiency and make the most out of the given computational resources, we allow each pipeline to perform early-stopping, and we store intermittent results (IRR) to still obtain a result even if the full training would time out. This rather practical choice greatly improved performance in general (solid line) and especially on large datasets (dashed line):
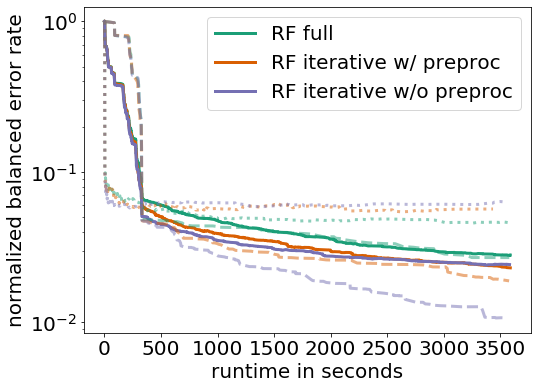
Furthermore, we decided to limit our search space to only algorithms that can be trained iteratively (iterative) to always guarantee to have a result. Since this subset mostly contains tree-based methods which often inherently contain feature selection steps we even went one step further and also removed expensive preprocessing (preproc).
Again, this change gave a large boost in performance especially on large datasets (compare the purple dashed line with the green dashed line):
Improvement 1: Model Selection Strategies
On the one hand, finding a well-performing model relies on the space of models considered for the search, but on the other hand, it is also crucial to use a good strategy to decide which model is best. During optimization we evaluate many ML pipelines aiming at minimizing the generalization error. This comes with two challenges:
- How to approximate the generalization error
- How to spread the available resources across all evaluations.
The first challenge is typically approached by using cross-validation, but this might not always be feasible (or even desirable) such that the simple holdout strategy would be preferable. The second challenge can be tackled by recent advances in multi-fidelity optimization (see also our paper and blogpost on BOHB), but again the optimal strategy depends on the dataset at hand and the resources we are willing to invest.
Here we show the performance of our system using different strategies to approximate the generalization error and to allocate resources for evaluating the pipeline:
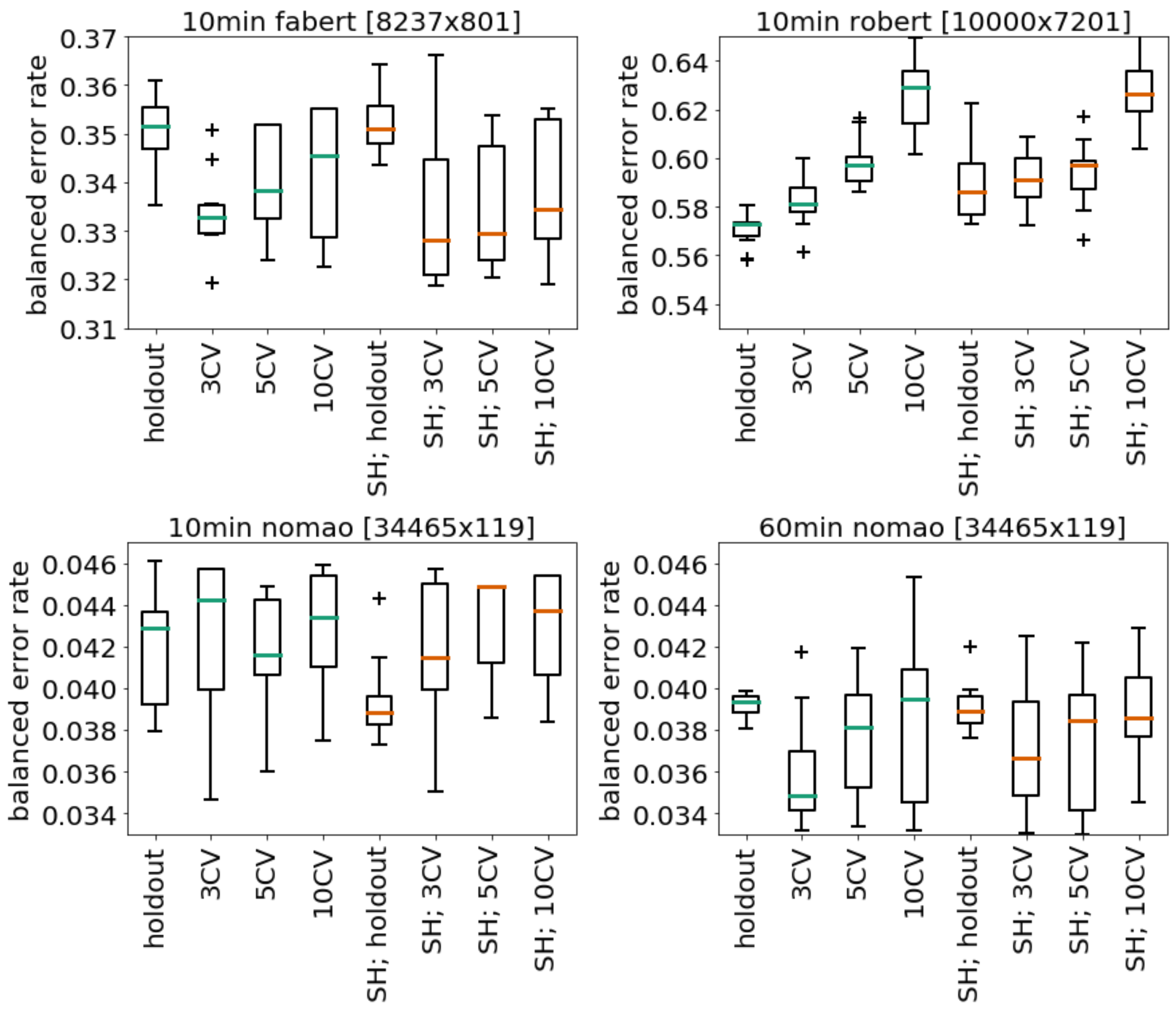 We can see that no single strategy performs best and thus we integrated all of them.
We can see that no single strategy performs best and thus we integrated all of them.
Improvement 2: Portfolio Building
Meta-learning is always a good idea to speed up optimization and turned out to be a crucial component for winning AutoML challenges. While the previous version of auto-sklearn relied on meta-features to determine which previous datasets are similar to the new one at hand, here, we followed a different strategy: having a single portfolio ready that contains pipelines that perform best on widely varying datasets, e.g. large and small datasets. Equipped with a set of pipelines that covers typical use cases we can directly start the optimization procedure.
Improvement 3: Automated Policy Selection
With improvement 1 and 2 we only added flexibility and features to cover a large set of use cases, but a prospective user would still need to choose a configuration of the AutoML system. Instead of leaving the user alone with this new meta-optimization problem we also automate auto-sklearn at this level by choosing the best model selection strategy for a new dataset at hand based on previously seen data.
Combining all of this, in a large scale study, we empirically compared our new system, auto-sklearn (2.0) to the old version, auto-sklearn (1.0), and observed a substantially reduced regret on the 39 datasets from the OpenML AutoML benchmark:

Thanks for reading this post, but this is only a brief summary, and more detailed insights and results can be found in the paper.