TL;DR: CARL is a benchmark for contextual RL (cRL). In cRL, we aim to generalize over different contexts. In CARL we saw that if we vary the context, the learning becomes more difficult, and making the context explicit can facilitate learning.
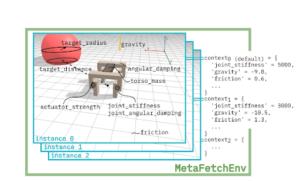
CARL makes the context defining the behavior of the environment visible and configurable. This way we can train for generalization over different instances (contexts) of the same environment. Here, we show all context features for Brax’ Fetch and sketch possible instantiations by setting the context features to different values. Fetch is embedded in the CARL environment controlling the instances.
To study generalization using the contextual setting, we require benchmarks with contextually extended environments to analyze RL agents’ generalization across environment variations. CARL is an open-sourced benchmark library that provides exactly this; thus, allowing reliable and reproducible studies of generalization in RL agents.
CARL extends existing RL environments for the contextual setting where the context defines the behavior of the environment explicitly, making it visible and configurable. This way, an RL agent can be trained for generalization over different instances (or contexts) of the same environment.

CARL includes several well-known environments like classic control and box2d from OpenAI’s gym, Google Brax’s walkers, different levels of Super Mario, and RNA folding environment. A user can take any one of these environments and select the contexts to be changed from a list of changeable contexts. This set of changeable contexts is often based on real-world physical properties related to the environments. For example, in the CartPole environment, the set of changeable contexts can be the gravity, length, or mass of the pole. These properties are intuitively understandable and making them individually adjustable allows a user to control the similarity of their sampled contexts. Moreover, it also opens up the study of generalization in RL along compositional axes, like seeing whether an agent trained individually on changing the length of the pole and the mass of the cart, can generalize to a setting where both of these factors change together.
CARL additionally allows a user to specify whether the context features are visible to the agent or hidden. In the former case, the context is appended to the state (in state-based environments), while in the latter the agent has to disentangle these itself. This also opens up the avenue of studying generalization in terms of the representations learned by an agent, since the ground-truth is already available to the user as the context values that change over instances.
Ultimately, the CARL benchmark is one step closer to creating general agents. If you are interested in the project, please see our paper and our GitHub page!
References
-
CARL: A Benchmark for Contextual and Adaptive Reinforcement Learning [Paper]NeurIPS 2021 Workshop on Ecological Theory of Reinforcement Learning, December 2021
-
Hyperparameters in Contextual RL are Highly Situational [Paper]NeurIPS 2021 Workshop on Ecological Theory of Reinforcement Learning, December 2021