Reinforcement learning (RL) has shown impressive results in a variety of applications. Well known examples include game and video game playing, robotics and, recently, “Autonomous navigation of stratospheric balloons”. A lot of the successes came about by combining the expressiveness of deep learning with the power of RL.
Already on their own though, both frameworks come with their own set of hyperparameters in need of proper tuning. Learning rates, regularization, optimizer and architecture design choices are just a few common hyperparameters that pop up in deep learning. In RL, among many others, careful consideration of how to trade off exploration and exploitation, how to discount rewards or how to handle large batch training is needed.
Combining DL and RL then comes with a potentially very large design space in which “standard rules of engagement” for hyperparameter optimization and AutoML of supervised learning methods might not work at all. Through its trial-and-error nature, RL does not keep learning with one fixed dataset. Instead RL interacts with an environment and generates new observations, which are neither independently nor identically distributed, which is in stark contrast to the usual Supervised Learning setting of deep learning.
In layman’s terms, RL starts out with a (usually random) behaviour policy to generate a bunch of observations. Then these observations are used to figure out how to improve the behaviour policy itself. This new and “improved” behaviour policy is then used to generate a new set of observations again, which are again used for policy improvement and so on. So the data that is used for learning is always changing.
Due to this complexity of the design space (stemming from the non-stationarity of RL and vastness of design choices) RL is known to be rather brittle. Not only are hyperparameter configurations and schedules not easily transferable between environments, often they don’t even behave similarly for different seeds within the same environment. If you further combine this brittleness with potentially very costly and lengthy training runs, manually searching for and crafting hyperparameter configurations or schedules quickly becomes a daunting and near impossible task. Anybody wanting to use RL for “non-standard tasks” for which experts have not already spent countless hours figuring out what does and does not work quickly becomes frustrated. All the more reasons to automate hyperparameter optimization for RL, aka AutoRL.
AutoRL, as such, is still relatively novel and not many approaches have been suggested. And, although learning from changing data might imply that dynamic tuning could be preferable, it remains unclear whether or when static tuning would be better than dynamic tuning. In the following we briefly discuss works from our group that applied both dynamic and static AutoML for RL, showing the advantages of both in comparison to manual tuning. We then discuss how model-based RL (MBRL) comes with further design decisions that additionally complicate hyperparameter tuning.
AutoRL in Our Group
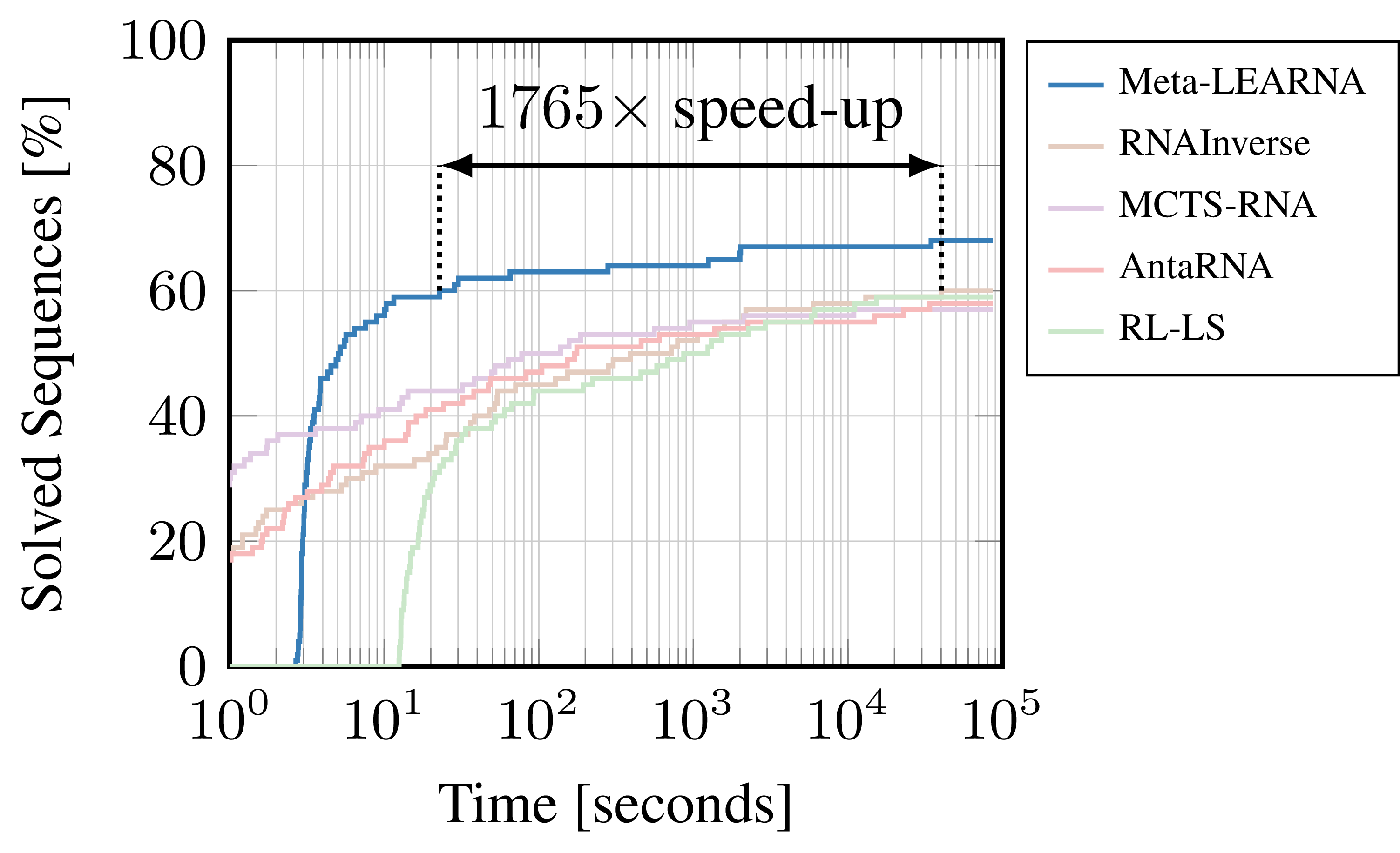
Comparison of the resulting RL performance (Meta-LEARNA) and state-of-the-art algorithms (RNAInverse, MCTS-RNA, antaRNA, RL-LS) on one of the most commonly used RNA Design benchmarks (Eterna100).
LEARNA
Back in 2018, when we started a project on RL for RNA design, there had been no previous work in the field using RL. We could not build on any previous work, leverage existing knowledge, or use architectures that weare known to work well for the problem at hand. Since RL is known to be sensitive to hyperparameter choicess, searching manually for well-performinggood configurations would probably have consumed weeks or months of tedious work on tuning and fine-tuning the algorithm formulation without any guarantees for success. We decided to economized this process by parameterizing the formulation of our RL algorithm and by framing the RNA design problem as an AutoRL problem. We used BOHB to predict configurations of our RL algorithm, jointly optimizing the formulation of the environment, the agent, and hyperparameters of the training pipeline to find the best RL algorithm for solving our problem. The result was LEARNA, an RL algorithm that achieved new state-of-the-art performance on two widely-used RNA design benchmarks and up to 1700 times speed-ups compared to the previous state-of-the-art.
For more information, check our previous blogpost on LEARNA, or our ICLR’19 paper or play around with the code on GitHub.
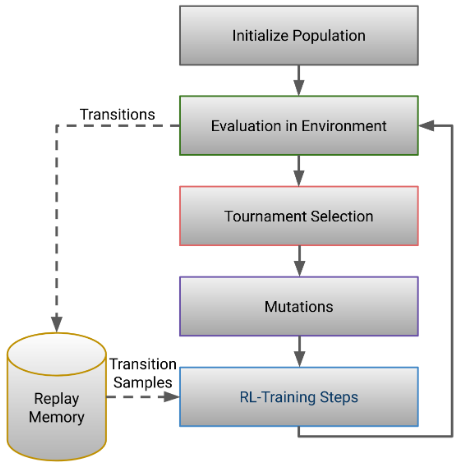
All components of SEARL at a glance
SEARL
In our ICLR’21 paper on Sample-efficient automated deep RL, or SEARL in short, we extend the approach of population-based training (PBT) and tackle the issues of sample-efficiency. SEARL is an AutoRL framework to optimize the hyperparameters of off-policy RL algorithms. In this framework, we jointly optimize the hyperparameters and the neural architecture while simultaneously training the agent. By sharing the collected experience across the population, we substantially increase the sample efficiency of the optimization procedure. We demonstrate the capabilities of SEARL in experiments optimizing a TD3 agent in the MuJoCo benchmark suite and a DQN agent in Atari environments. SEARL reduces the number of environment interactions needed for meta-optimization by up to an order of magnitude compared to random search or population-based training. SEARL is in the proceedings of ICLR this year and for more details of all of SEARL’s components we refer the reader to our paper or source code on GitHub.
AutoRL for Model-Based RL
As discussed above, RL itself is very sensitive to hyperparameter choices. This is the case even more so for model-based RL (MBRL) because of the added complexity of learning a dynamics model. MBRL differs from the more commonly used model-free RL setting as it iterates between training the dynamics model and then uses this model to find well performing policies to execute which generate new data with which the model is further refined. This interaction of the model and policies places additional requirements on the expertise of the humans tuning them.
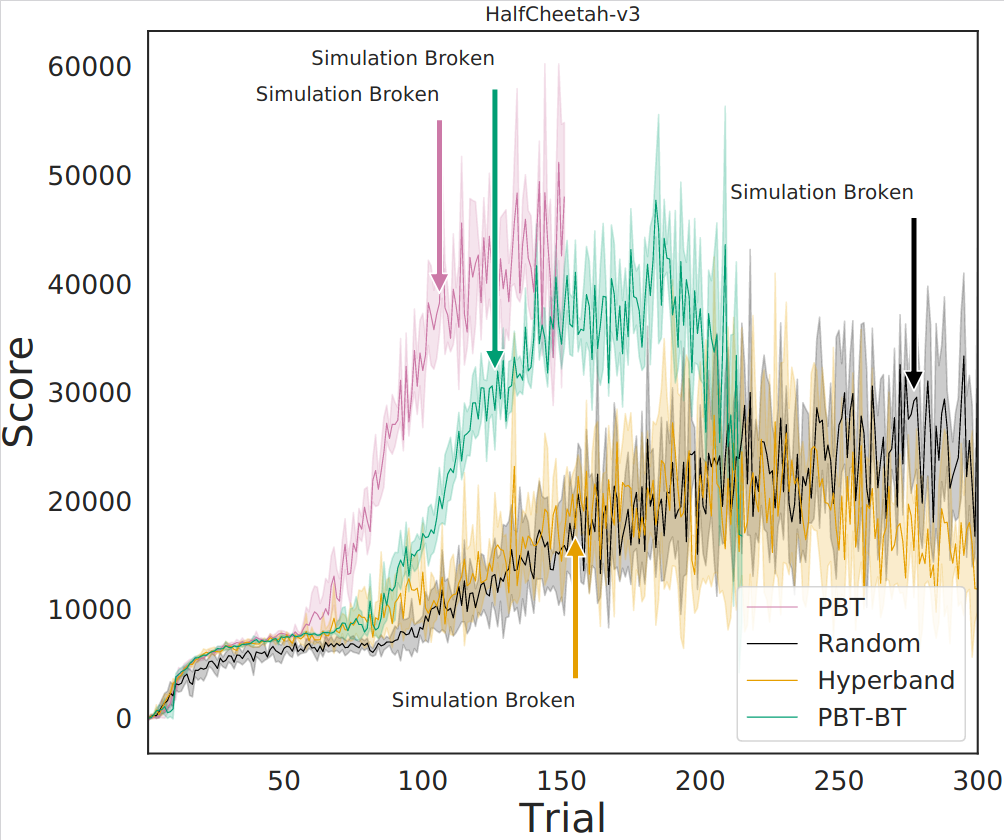
AutoRL for MBRL can improve an agent so much that it breaks the simulator.
In this work, we examined how static HPO (such as used in LEARNA) and dynamic HPO (as used in PBT/SEARL) could help in improving the performance of a state-of-the-art MBRL method. Our results show that AutoRL can significantly improve the performance compared to expert-tuned default configurations. In one case, it even enabled the MBRL agent to find policies that performed so well that the simulator used could not keep up and broke.
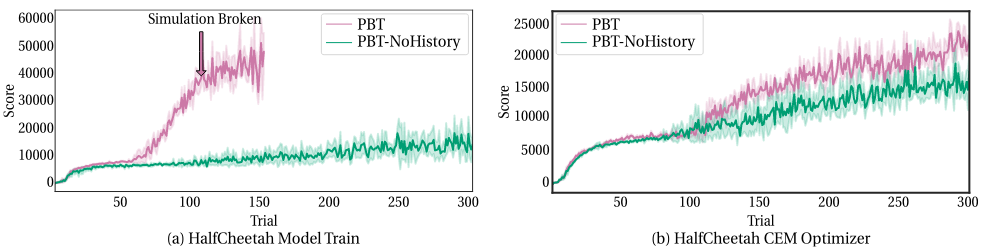
When dynamically configuring MBRL agents, the data history plays an important role.
Delving deeper into the requirements of researchers trying to tune MBRL methods, we analyse and gain insights into static and dynamic tuning of these methods. For example, our results show that dynamic tuning can lead to better final performance of an agent than static tuning could. However, the found schedules are mostly not transferable, even across different seeds. Instead, if a more robust and well performing final configuration is required, static tuning is preferable. Further, one crucial aspect in enabling dynamic configuration for MBRL was making sure that agents have a consistent history. Thus, when using a PBT style approach, not only did we copy over network weights but also an agents replay-buffer. This was an important factor in reliably breaking the simulator and achieving dramatic performance improvements as can be seen in the figure above.
In the paper we provide more detailed analysis and also explore the problem of objective mismatch of learnt models, their uncertainties and their performances.
For a more detailed discussion (and videos of the simulation breaking behaviour) that focuses more on the MBRL aspects please checkout the dedicated BAIR blog-post or our AISTATS’21 paper.
Take Home Message
Reinforcement Learning provides exciting new challenges for AutoML that can be solved both with dynamic and static tuning methods. If these challenges are carefully considered, the resulting AutoRL methods can greatly improve performance and robustness of the RL agents. However, AutoRL is still relatively novel and we can expect to see exciting new approaches in the future. In the long run, we hope that with the help of AutoRL we will be able to have truly “off-the-shelf” agents such that RL requires less expert knowledge and is more broadly applicable.