Carolin Benjamins, Theresa Eimer, Frederik Schubert, Aditya Mohan, Sebastian Döhler, André Biedenkapp, Bodo Rosenhahn, Frank Hutter and Marius Lindauer
TLDR: We can model and investigate generalization in RL with contextual RL and our benchmark library CARL. In theory, without adding context we cannot achieve optimal performance and in the experiments we saw that using context information can indeed be beneficial – context matters!
While Reinforcement Learning (RL) has shown successes in a variety of domains, including game playing [Silver et al. 2016, Badia et al. 2020], robot manipulation [Lee et al. 2020, Ploeger et al. 2020] and nuclear fusion [Degrave et al. 2022], modern RL algorithms are not designed with generalization in mind, making them brittle when faced with even slight variations of their environment [Yu et al. 2019, Meng et al. 2020, Lu et al. 2020]. To address this limitation, recent research has increasingly focused on generalization capabilities of RL agents.
Ideally, general agents should be capable of zero-shot transfer to previously unseen environments and robust to changes in the problem setting while interacting with an environment [Zhang et al. 2021, Fu et al. 2021, Sodhani et al. 2021, Kirk et al. 2023]. Steps in this direction have been taken by proposing new problem settings where agents can test their transfer performance, e.g. the Arcade Learning Environment’s flavors [Machado et al. 2018] or benchmarks utilizing Procedural Content Generation (PCG) to increase task variation, e.g. ProcGen [Cobbe et al. 2020], NetHack [Küttler et al. 2020] or Alchemy [Wang et al. 2021].
While these extended problem settings in RL have expanded the possibilities for benchmarking agents in diverse environments, the degree of task variation is often either unknown or cannot be controlled precisely.
We believe that generalization in RL is held back by these factors, stemming in part from a lack of problem formalization [Kirk et al. 2023]. In order to facilitate generalization in RL, contextual RL (cRL) proposes to explicitly take environment characteristics, the so-called context [Hallak et al. 2015], into account. This inclusion enables precise design of train and test distributions with respect to this context. Thus, cRL allows us to reason about zero-shot generalization capabilities of RL agents and to quantify their generalization performance.
Overall, cRL provides a framework for both theoretical analysis and practical improvements that supports different settings within zero-shot generalization, e.g. generalizing across a distribution of instances similar to the one seen in training, solving a single hard instance after training on simpler ones or transferring performance of fully trained policies from one instance set to another.
In order to empirically study cRL, we introduce our benchmark library CARL, short for Context-Adaptive Reinforcement Learning. CARL collects well-established environments from the RL community and extends them with the notion of context. We use our benchmark library to empirically show how different context variations can drastically increase the difficulty of training RL agents, even in simple environments. We further verify the intuition that allowing RL agents access to context information is beneficial for generalization tasks in theory and practice.
Providing Benchmarks for cRL Research

In order to study generalization in cRL in a principled manner, we extend common RL benchmarks with context information to form a new benchmark library, CARL. This enables researchers to use well-known problem settings, but also define interesting train and test distributions. In our release of CARL benchmarks, we include and contextually extend classic control and box2d environments from OpenAI Gym, Google Brax’ walkers, a selection from the DeepMind Control Suite, an RNA folding environment as well as Super Mario levels, see Figure 1.
We provide discrete as well as continuous environments with vector-based as well as image-based observation spaces. The difficulty of the environments ranges from relatively simple in classic control tasks to very hard in Mario or RNA. The context information for most of these benchmarks is comprised of physical properties like friction or mass, making it intelligible to humans as well as relevant in practical tasks. Overall, CARL focuses on popular environments and will grow over time, increasing the diversity of benchmarks. Already now, CARL provides a benchmarking collection that tasks agents with generalizing in addition to solving the problem most common in modern RL while providing a platform for reproducible research.
The Value of Context in Practice
We demonstrate that varying context increases the difficulty of the task, already for simple environment settings. Varying the physical properties of classic control tasks, like Pendulum or CartPole, results in diverse environment dynamics. Agents trained on single contexts, fail to generalize to these altered environment settings. Figure 2 shows this effect for Pendulum on several context features.
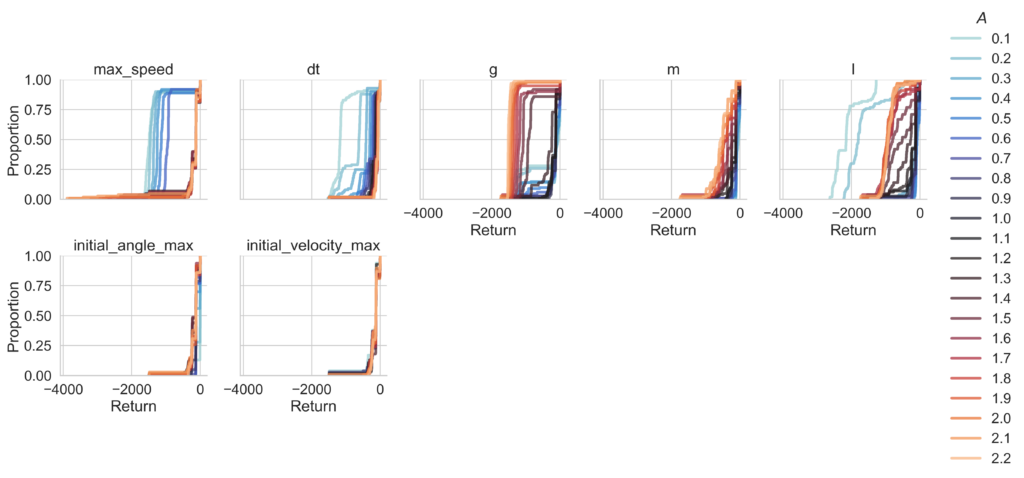
Even when we train the agent on context variations, this general agent does not match the performance of specialized agents (trained on one context each). For example, on CartPole the general agent reaches the solution threshold on 40% fewer instances than separate general agents, as shown in Figure 3.

We investigate if this effect can be mitigated by providing context information to the agent by naively concatenating it to the state and see that agents with context information concatenated to the state tend to learn faster and reach higher final performances across most environments in our experiments (see Figure 4 for an example).

When evaluating these agents on different variations of interpolation and extrapolation settings, we see that the test behavior changes remarkably when the agent is context-aware, focusing on the training distribution and thus becoming more predictable.
Concluding Remarks
Toward our goal of creating general and robust agents, we need to factor in possible changes in the environment. We propose modeling these changes with the framework of contextual Reinforcement Learning (cRL) in order to better reason about what demands cRL introduces to the agents and the learning process, specifically regarding the suboptimal nature of conventional RL policies in cRL. With CARL, we provide a benchmark library that contextualizes popular benchmarks and is designed to study generalization in cRL. It allows us to empirically demonstrate that contextual changes disturb learning even in simple settings and that the final performance and the difficulty correlate with the magnitude of the variation. We also verify that context-oblivious policies are not able to fully solve even simple contextual environments. Furthermore, our results suggest that exposing the context to agents even in a naive manner impacts the generalization behavior, in some cases improving training and test performance compared to non-context-aware agents. We expect this to be a first step towards better solution mechanisms for contextual RL problems and therefore one step closer to general and robust agents.
References
[Badia et al. 2020] A. Badia, B. Piot, S. Kapturowski, P. Sprechmann, A. Vitvitskyi, Z. Guo, and C. Blundell. Agent57: Outperforming the atari human benchmark. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pp. 507–517. PMLR, 2020.
[Cobbe et al. 2020] K. Cobbe, C. Hesse, J. Hilton, and J. Schulman. Leveraging procedural generation to benchmark reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning, ICML, volume 119 of Proceedings of Machine Learning Research, pp. 2048–2056. PMLR, 2020.
[Degrave et al. 2022] J. Degrave, F. Felici, J. Buchli, M. Neunert, B. Tracey, F. Carpanese, T. Ewalds, R. Hafner, A. Abdolmaleki, D. de Las Casas, C. Donner, L. Fritz, C. Galperti, A. Huber, J. Keeling, M. Tsimpoukelli, J. Kay, A. Merle, J. Moret, S. Noury, F. Pesamosca, D. Pfau, O. Sauter, C. Sommariva, S. Coda, B. Duval, A. Fasoli, P. Kohli, K. Kavukcuoglu, D. Hassabis, and M. Riedmiller. Magnetic control of tokamak plasmas through deep reinforcement learning. Nature, 602(7897):414–419, 2022.
[Fu et al. 2021] X. Fu, G. Yang, P. Agrawal, and T. Jaakkola. Learning task informed abstractions. In M. Meila and T. Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 3480–3491. PMLR, 18–24 Jul 2021b.
[Hallak et al. 2015] A. Hallak, D. Di Castro, and S. Mannor. Contextual markov decision processes. arXiv:1502.02259 [stat.ML], 2015.
[Kirk et al. 2023] R. Kirk, A. Zhang, E. Grefenstette, and T. Rocktäschel. A survey of zero-shot generalisation in deep reinforcement learning. J. Artif. Intell. Res., 76:201–264, 2023.
[Küttler et al. 2021] H. Küttler, N. Nardelli, A. Miller, R. Raileanu, M. Selvatici, E. Grefenstette, and T. Rocktäschel. The nethack learning environment. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, 2020.
[Lee et al. 2020] J. Lee, J. Hwangbo, L. Wellhausen, V. Koltun, and M. Hutter. Learning quadrupedal locomotion over challenging terrain. Science in Robotics, 5, 2020a.
[Lu et al. 2020] M. Lu, Z. Shahn, D. Sow, F. Doshi-Velez, and L. H. Lehman. Is deep reinforcement learning ready for practical applications in healthcare? A sensitivity analysis of duel-ddqn for hemodynamic management in sepsis patients. In AMIA 2020, American Medical Informatics Association Annual Symposium, Virtual Event, USA, November 14-18, 2020. AMIA, 2020.
[Machado et al. 2018] M. Machado, M. Bellemare, E. Talvitie, J. Veness, M. Hausknecht, and M. Bowling. Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents. J. Artif. Intell. Res., 61: 523–562, 2018.
[Meng et al. 2020] T. Meng and M. Khushi. Reinforcement learning in financial markets. Data, 4(3):110, 2019.
[Ploeger et al. 2020] Kai Ploeger, Michael Lutter, and Jan Peters. High acceleration reinforcement learning for real-world juggling with binary rewards. In Jens Kober, Fabio Ramos, and Claire J. Tomlin (eds.), 4th Conference on Robot Learning, CoRL 2020, 16-18 November 2020, Virtual Event / Cambridge, MA, USA, volume 155 of Proceedings of Machine Learning Research, pp. 642–653. PMLR, 2020. URL https://proceedings.mlr. press/v155/ploeger21a.html.
[Silver et al. 2016] D. Silver, A. Huang, C. Maddison, A. Guez, L. Sifre, G. Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis. Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489, 2016.
[Sodhani et al. 2021] S. Sodhani, A. Zhang, and J. Pineau. Multi-task reinforcement learning with context-based representations. In M. Meila and T. Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 9767–9779. PMLR, 18–24 Jul 2021b.
[Wang et al. 2021] J. Wang, M. King, N. Porcel, Z. Kurth-Nelson, T. Zhu, C. Deck, P. Choy, M. Cassin, M. Reynolds, H. Song, G. Buttimore, D. Reichert, N. Rabinowitz, L. Matthey, D. Hassabis, A. Lerchner, and M. Botvinick. Alchemy: A benchmark and analysis toolkit for meta-reinforcement learning agents. In Joaquin Vanschoren and Sai-Kit Yeung (eds.), Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks, 2021.
[Yu et al. 2019] T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on Robot Learning (CoRL), 2019.
[Zhang et al. 2021] A. Zhang, S. Sodhani, K. Khetarpal, and J. Pineau. Learning robust state abstractions for hidden-parameter block mdps. In 9th International Conference on Learning Representations, ICLR 2021. OpenReview.net, 2021b.