When researching and developing new hyperparameter optimization (HPO) methods, a good collection of benchmark problems, ideally relevant, realistic and cheap-to-evaluate, is a very valuable resource. While such collections exist for synthetic problems (COCO) or simple HPO problems (Bayesmark), to the best of our knowledge there is no such collection for multi-fidelity benchmarks. With ever-growing machine learning (ML) models and datasets, the need for multi-fidelity optimization methods (such as BOHB [blog; paper; code] and DEHB [paper; code]) increases since they can effectively optimize such expensive problems by trading off cheap approximations and expensive evaluations on the real target. In our lab, we love to develop open-source tools and with HPOBench we want to to fill this gap by providing a set of flexible, reproducible and diverse benchmark problems. In the following, we will briefly describe HPObench by means of these features and take a peek at the outcomes of a large-scale comparison of optimization algorithms presented in our paper. For more information, we refer to our paper (here on arXiv) or our code on Github.
Flexibility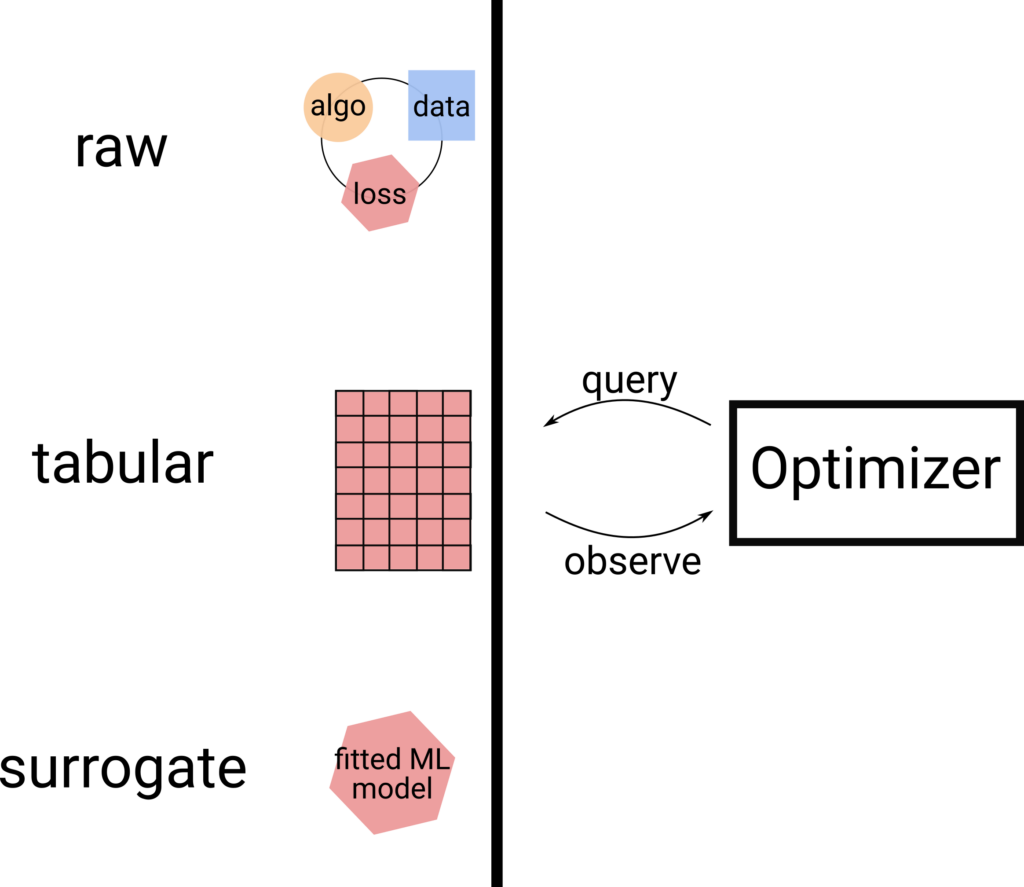
We aim for fast, but still realistic benchmarks. Therefore we consider three types of benchmarks. First, there are raw benchmarks, which actually evaluate a potentially costly algorithm to compute the loss function. Second, there are tabular benchmarks, which are pre-computed table lookups. Third, there are surrogate benchmarks, where an ML model emulates the real benchmark. Surrogate and tabular benchmarks are a well used cheap-to-evaluate alternative to raw benchmarks, however, they either rely on a trained ML model or require discretizing the searchspace. Raw benchmarks, in contrast, can be very costly to use and might be even infeasible to evaluate without sufficient compute resources.
Reproducibility
Besides providing all of these with a unified interface to set up experiments fast, we made sure that these benchmarks are available long-term. For this, we packaged each benchmark in its own Singularity container (https://singularity.hpcng.org/). This not only freezes all dependencies and thus frees a user from the necessity to satisfy all of them in one environment (in addition to what the optimization algorithm needs), it also makes maintenance much simpler. Here are the steps, we executed for every single benchmark in our library:
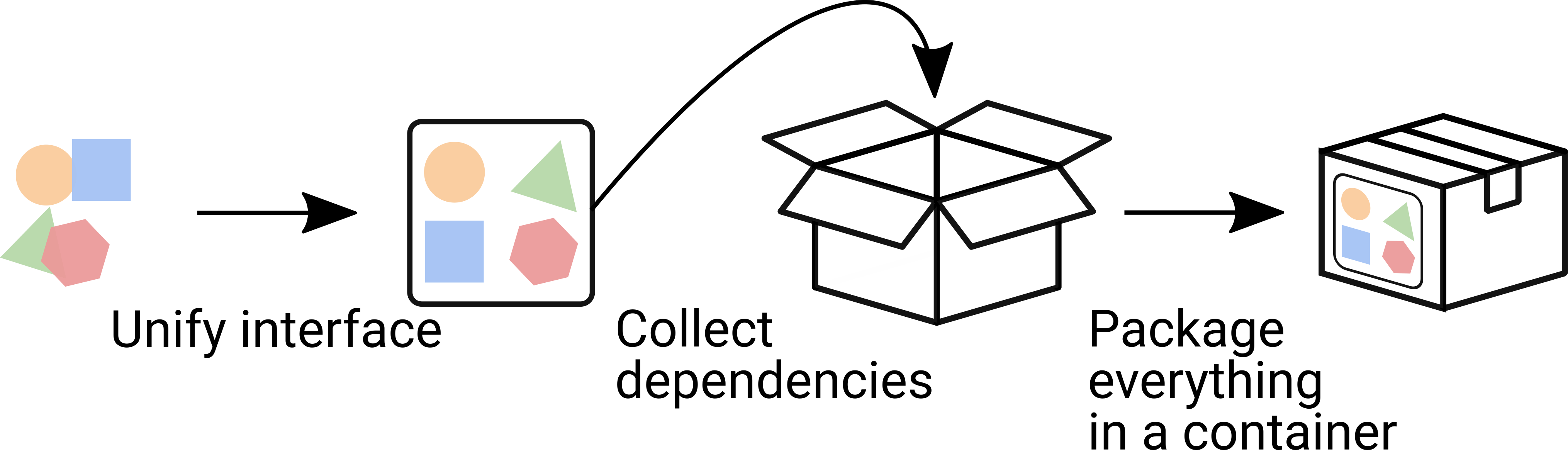
Diversity
HPOBench provides 7 existing benchmark families from RL, NAS and HPO available as raw, tabular or surrogate algorithms enabling fast experimenting. We extended these with 5 more and new benchmark families based on ML algorithms evaluated on popular OpenML datasets. These are available as both, raw and tabular benchmarks and each benchmark features at least one fidelity dimension allowing to evaluate multi-fidelity optimization algorithms. In total there are more than 100 benchmark problems to compare multi-fidelity and also black-box optimization algorithms.
Our current collection comprises the following benchmarks:
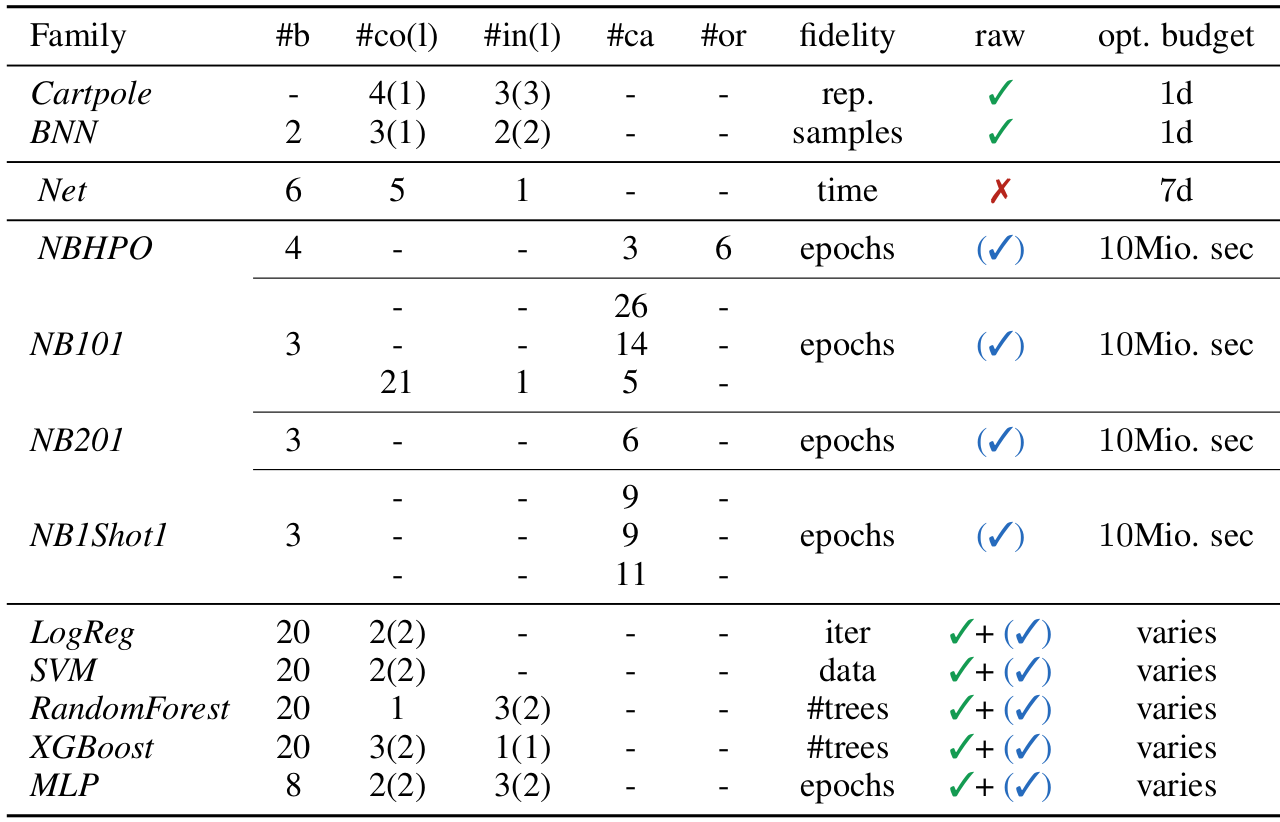
Experiments
To demonstrate that our new library works with a large set of optimization algorithms, we ran implementations of optimization algorithms from 6 well known optimization tools (SMAC, DEHB, BOHB, Dragonfly, Ray, Optuna). We evaluated 6 black box optimization methods (only evaluating the highest fidelity) and 8 multi-fidelity optimization methods.
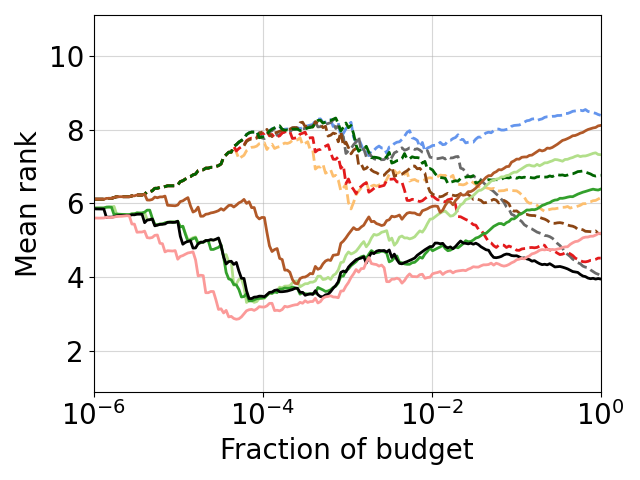

Here, we show the average-rank-over time averaged across the 6 previously existing benchmark families for a subset of optimizers. We can favourably see that the black-box optimizers (dashed lines) perform inferior to the multi-fidelity optimizers and indeed provide speedups with small budgets. Given enough budget, the black-box optimizers might catch up eventually, but this happens only after a substantial fraction of the budget has been used.
This is even more obvious when looking at ranks, directly comparing black-box optimizers with their multi-fidelity extension, e.g. DE & HB & DEHB and BO & HB & BOHB and SMAC & HB & SMAC-HB (from left to right; colors are the same as in the plot above).
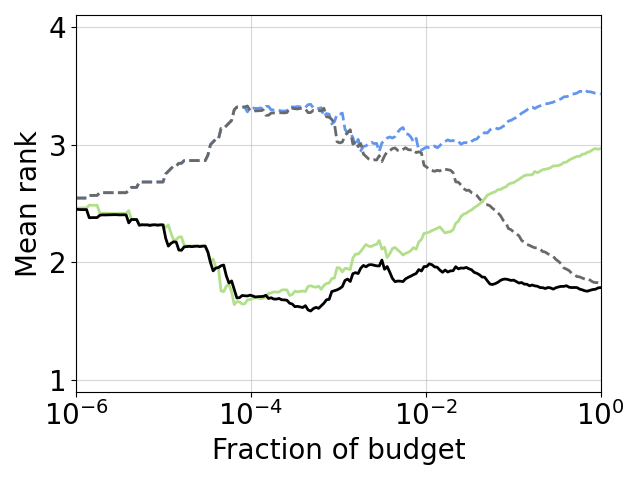
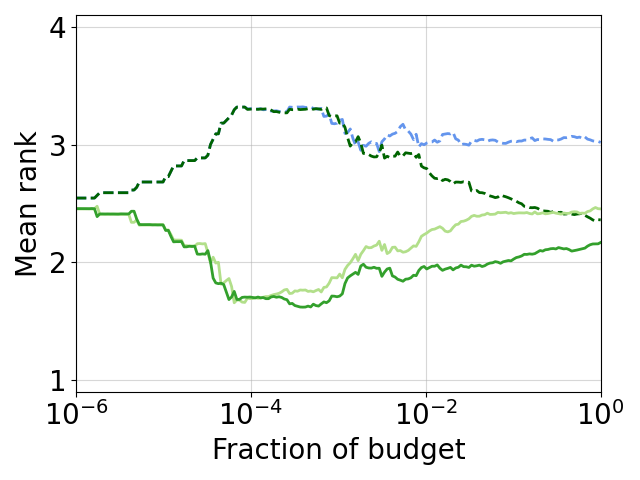
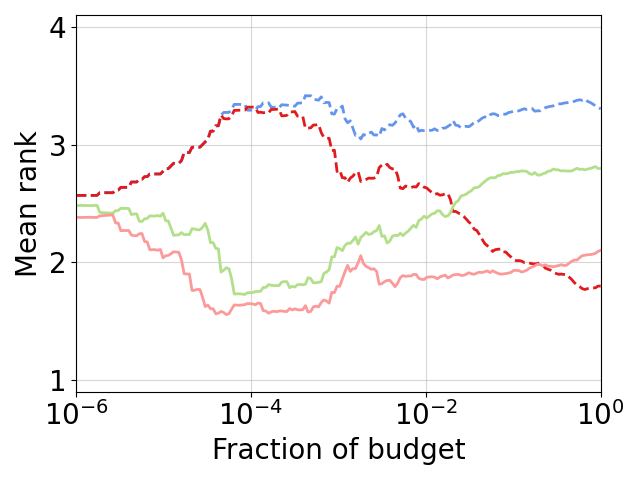
The multi-fidelity methods perform superior from the beginning on and for a large fraction of the budget. At some point the black-box version (dashed line) catches up and outperforms Hyperband (light green line), while the multi-fidelity version still stays superior.
What else?
You can find more details and further experiments in our paper. Please also try our benchmarks (https://github.com/automl/HPOBench). Finally, we’re happy to receive feedback, stars and new benchmarks via pull-requests.