Theresa Eimer, Marius Lindauer, Roberta Raileanu
TL;DR: Hyperparameter Optimization tools perform well on Reinforcement Learning, outperforming Grid Searches with less than 10% of the budget. If not reported correctly, however, all hyperparameter tuning can heavily skew future comparisons.
Reinforcement Learning (RL) is an interesting domain for Hyperparameter Optimization (HPO), with complex settings and algorithms that rely on a number of important hyperparameters for both data generation and learning. Since RL algorithms tend to be very sensitive to their hyperparameters, RL and HPO seem like a match made in heaven – and yet, most RL research papers that report their hyperparameter tuning use Grid Search. Maybe only a small subset of hyperparameters have to be tuned, making Grid Search a good choice? Aren’t advanced HPO tools hard to use with RL? Is there something about RL that makes tuning hyperparameters uniquely hard?
The answer is NO on all accounts: in our ICML 2023 paper we show that adopting HPO tools and practices has the potential to make RL research more efficient, accessible and reproducible.
Hyperparameters in RL
Before tuning any algorithm, we first establish why the hyperparameters in RL are important in the first place. Therefore we analyze sweeps across several hyperparameters of PPO [Schulman et al. 2017], DQN [Mnih et al. 2013] and SAC [Haarnoja et al. 2018] on a diverse set of classic control, locomotion and grid world environments. Our results show that
- For any given algorithm and environment, a majority of its hyperparameters are important to successful learning;
- The hyperparameters don’t have complex interactions or narrow regions of good performance;
- The difference in both final performance and overall behavior of the same hyperparameter configuration is significant between seeds.
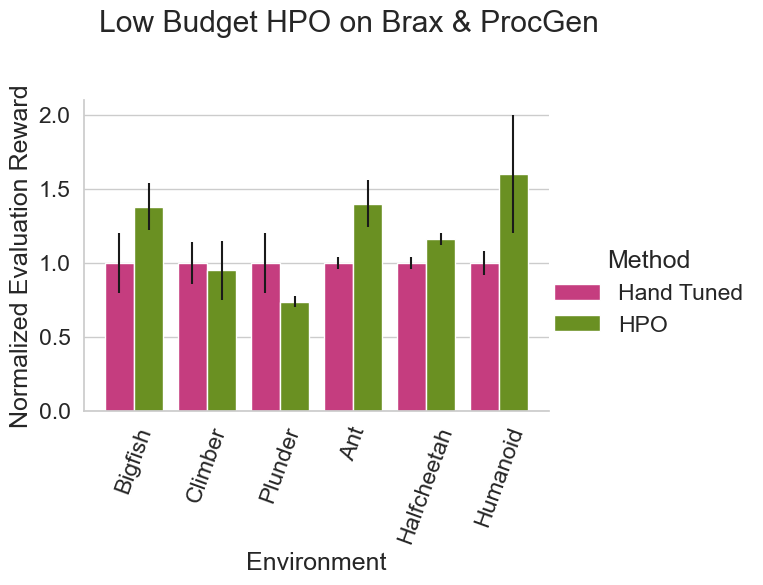
What does this mean? While each of the hyperparameters of RL algorithms don’t seem to be hard to tune individually, it makes sense to tune as many of them as possible – and include some measure of how hyperparameter configurations vary between seeds. Grid Search, scaling poorly with the number of hyperparameters, is a very inefficient option in this setting.
It also means the seed is an important factor in tuning RL, probably more so than in tuning supervised learning, since it has a significant impact on learning as well as data collection. Taking the seed into account when tuning RL algorithms is crucial.
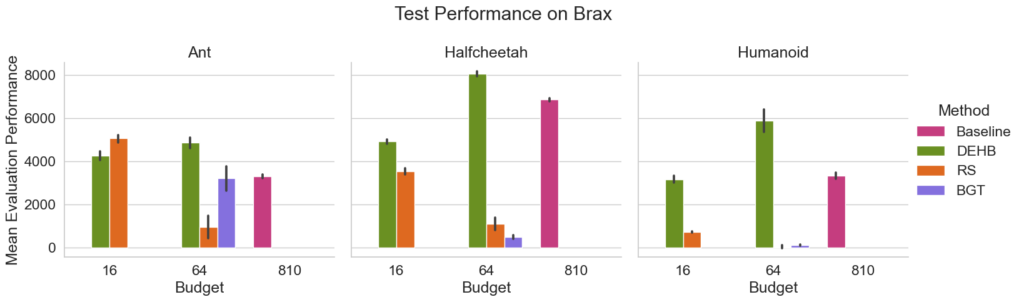
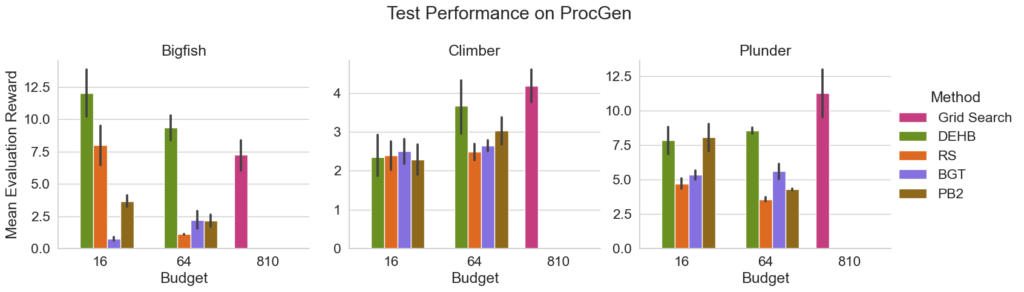
Thankfully modern HPO tools are well equipped to deal with large search spaces and HPO provides best practices to handle multiple seeds [Eggensperger et al. 2019]. Tuning the state-of-the-art algorithms PPO [Schulman et al. 2017] and IDAAC [Raileanu & Ferguson 2021] on Brax [Freeman et al. 2021] and ProcGen [Cobbe et al. 2020], respectively, both with rather large search spaces of 11 and 14 hyperparameters, we see that even the large scale Grid Search in the original IDAAC paper with its budget of 810 algorithm runs is on average outperformed by DEHB [Awad et al. 2021] with only 64 runs (see the Figure below). The results on Brax are similar, showing the benefits of using state-of-the-art HPO methods.
Tune and Test Settings – A Reproducibility Hazard
But there is something that needs to be addressed with this result: performance on the tuning seeds compared to test seeds is different, sometimes significantly so. This indicates that the incumbent configurations have a hard time generalizing to new seeds. Take PB2’s incumbents and test seed performance on Bigfish: the incumbent performs about 8x better than the same configuration on test seeds. Of course we expect a drop in performance from incumbent to test. The issue is that reporting standards in RL do not include the tuning seeds. That means when using a paper as a baseline that does not state which seeds are used for tuning, whether the comparison is a fair one depends entirely on whether the tuning seeds are by chance included in the test setting. Since the difference between tune and test seeds can skew the results so dramatically, even an overlap in seeds can completely invalidate the results. And yet, currently it is very hard or impossible to ensure adhering to proper scientific standards since the information is simply not available.
Getting Started with HPO for RL
We therefore want to provide resources to RL researchers who want to improve their HPO: First, we open source hydra sweeper versions of DEHB, PBT [Jaderberg et al. 2017], PB2 [Parker-Holder et al. 2020] and Bayesian Generational Training [Wan et al. 2022]. Via hydra sweepers, HPO can happen directly on the training code without alterations except for returning a performance metric. Only an additional hydra config file is required. Check them out at www.github.com/facebookresearch/how-to-autorl as well as SMAC’s new hydra sweeper at: https://github.com/automl/hydra-smac-sweeper
Secondly, we summarize best practices in HPO and consolidate them with important points for RL reproducibility. The result is a checklist researchers can use to plan their experiments and report all details that are relevant for easy reproducibility. Here’s a condensed version:

If you want to include the full version of this checklist in your paper, you can find a LaTeX template at: www.github.com/facebookresearch/how-to-autorl
What’s next?
Even though our results are generally positive, we also identify several challenges that remain in tuning RL algorithms, such as the large discrepancy in performance between seeds. Furthermore, with our limited budget, the PBT variations we tested did not perform as well as we had hoped, likely due to our restrictive budgets. Since they are dynamic configurators, however, they still hold enormous potential even if further research is required for them to be efficient HPO tools. Learnt hyperparameter paradigms could solve both of these problems at once, even though there is not a lot of work on this topic in RL as of yet – so plenty of potential for future AutoRL [Parker-Holder et al. 2022] endeavors!
Here is the link to try our sweepers yourself: https://github.com/facebookresearch/how-to-autorl
The link to our reproducibility checklist: https://github.com/facebookresearch/how-to-autorl/blob/main/checklist.pdf
For more details and our full results, see our paper: https://arxiv.org/pdf/2306.01324.pdf