Authors: Difan Deng and Marius Lindauer
TL;DR
In our paper, we present a one-shot neural architecture search space for time series forecasting tasks. Our search space contains a hybrid network that contains a Seq Net (for instance, transformers and RNNs that process sequences directly) and a Flat Net (for instance, MLPs that handle each variable independently). This search space allows the optimizers to arbitrarily combine the desired architecture components to propose a novel architecture for each different task. Experiments show that by applying DARTS on top of our search space, we can search for lightweight, high-performing forecasting architectures across different forecasting tasks.
Deep Learning and NAS for Time Series Forecasting
Time series forecasting tasks aim to predict the values of the target variables for a number of iterations after a certain time step with the observed same variables and several other feature variables. Many architectures (Bai et al. 2018, Oreshkin et al. 2019, Nie et al. 2022, Zeng et al. 2022) are proposed to solve this problem.
While the previous NAS forecasting work (Deng et al. 2022) mainly focused on the search space for homogeneous models. However, it is still being determined if one could design a one-shot search space (Liu et al. 2018) that connects arbitrary components to form a new architecture.
Searching for the Optimal Forecasting Architectures
Our search space is hierarchical and has three levels, from low to high: the operation level, the micro network level, and the macro architecture level.
The operation level is a cell-based search space where each cell contains a fully connected, directed acyclic graph where each edge contains multiple operations. This includes: MLPMixer, LSTM, GRU, Transformer, TCN, SepTCN, and skip connections for Seq Net, and Linear layers, N-BEATS modules, and skip connections for Flat Net.

The micro network level design integrates Flat Net and Seq Net architectures, where Flat Net processes past targets with encoder layers to produce backcast and forecast outputs, and Seq Net encodes past observed values and utilises decoders for final forecasting.

Finally, the macro network level design combines Flat Net and Seq Net architectures to leverage their complementary strengths. The past targets are first processed by the Flat Net, producing forecast feature maps, which are then fed into the Seq Net‘s encoders and decoders along with known future inputs. The final forecast is a weighted sum of the outputs from both Flat Net and Seq Net, enhancing overall predictive performance and adaptability across various time series forecasting tasks.
Empirical Results

We show that DARTS-TS could find the architectures with optimal performances (see table). Additionally, we show that the architectures proposed by DARTS-TS require much less resources and computation time compared to the other baselines.
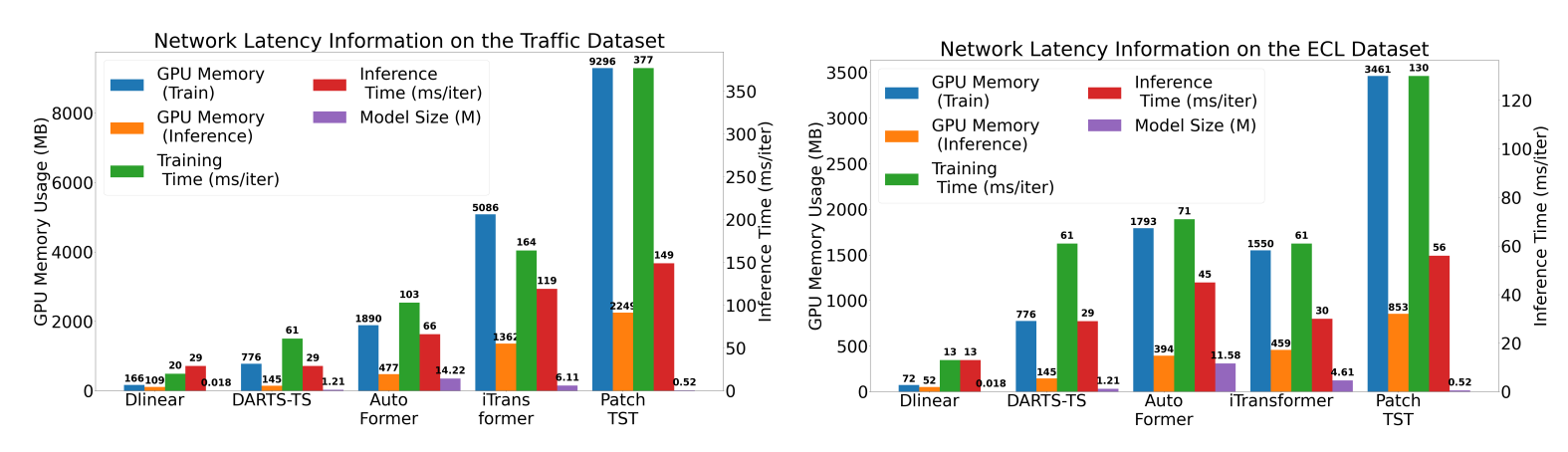
Conclusion
Our paper emphasises the importance of leveraging deep learning and NAS to improve time series forecasting models. By addressing the specific challenges of temporal dependencies and optimising architecture design, these methods can significantly enhance forecasting accuracy and efficiency. For further details and comprehensive insights, we recommend to read the full paper: https://arxiv.org/abs/2406.05088