RL agents, just like humans, often benefit from a difficulty curve in learning [Matiisen et al. 2017, Fuks et al. 2019, Zhang et al. 2020]. Progressing from simple task instances, e.g. walking on flat surfaces or towards goals that are very close to the agent, to more difficult ones lets the agent accomplish much harder feats than possible without such a curriculum, e.g. balancing over various obstacles on the ground or reaching even far away goals on slippery surfaces [Wang et al. 2019, Klink et al. 2020].
Several such Curriculum Learning approaches have been successful in RL towards open-endedness and goal-based RL with more recent progress in contextual RL. Most of them, however, assume some measure of domain knowledge of the instance space or in the form of an instance generator.
We propose SPaCE, a general approach that can be deployed for any agent with a value function and task instances identified by their context without any additional information. We believe this is an important factor in future applications, including AutoML where in-depth knowledge about target algorithm instances is not always as readily available as common in RL.
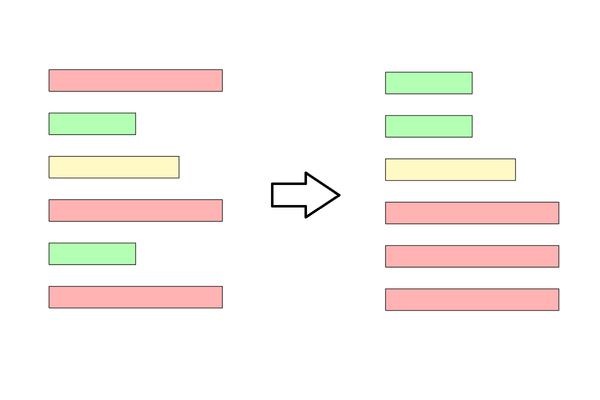

Figure 1: Unsorted instances compared to an instance curriculum examples of easy and hard instances of the BipedalWalker environment as used by Wang et al. 2019.
Contextual Reinforcement Learning
Contextual RL formalizes variations of a task, called instance, as their own Markov Decision Processes (MDP) with shared state and action spaces, but changes to reward function and transition dynamics. Therefore different instances can change the goals the agent should reach, the environment’s dynamics or both at the same time. Formally a contextual MDP M = {M_i}_{i \in I} with I being the set of instances. Each instance is characterized by its context c_i. In the walker example in Figure 1, the context would be the ground profile. We assume that such expert knowledge is available and is provided to the agent for distinguishing between instances.
This setting encompasses goal-based RL and adds the additional difficulty of variations in environment dynamics. That means it is a challenging setting, requiring generalization across possibly heterogeneous contexts and raising the issue of forgetting previously learnt concepts. It is also, however, much closer to what we would expect an agent to accomplish in real-world settings, fluently accomplishing its task regardless of changes to its environment. Therefore we believe it to be an important direction of future research in RL.
Generating Context Curricula
We assume we are given a set of instances without any further knowledge about their difficulty and an agent with an approximated value function V. Value-based reinforcement learning agents inherently have such a value function approximation, as do state-of-the-art actor-critic approaches; so this applies to many common RL algorithms. We then want to order the instances in a way that always provides the agent with a set of instances of appropriate difficulty to train on in order to maximize learning progress. Choosing instances the agent has already mastered will not yield much progress while choosing instances that are currently too hard will also not provide a good learning stimulus.
Our criterion for rating instance difficulty is thus the agent’s performance improvement capacity (PIC) for each instance. It is the difference in the agent’s value estimation from one iteration to the next; so it describes how much the agent thinks it has improved on that instance. Using the PIC as a proxy for instance difficulty adds little computational overhead as it does not require any additional steps in the environment.
Figure 2 shows the curriculum generation using SPaCE. In each curriculum iteration, we first see if the value function still shows changes above a given threshold compared to the previous iteration. If not, we increase the learning stimulus by increasing the instance set size. Then we compute the PIC for all instances and train on the instances with the highest PIC for this iteration.
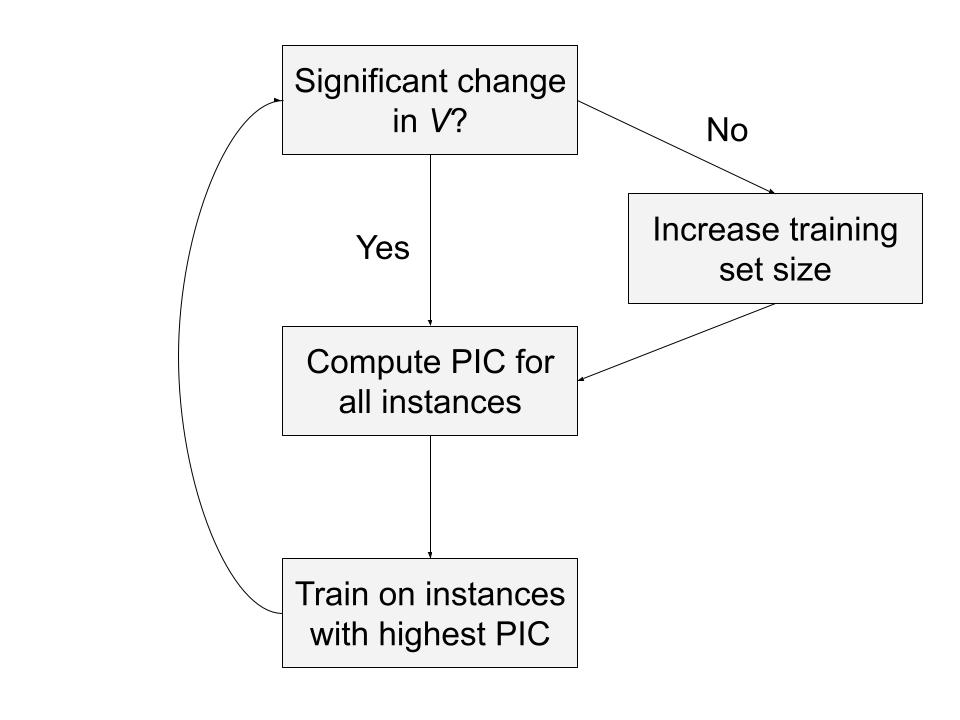

Figure 2: Left: SPaCE curriculum generation, Right: SPaCE pseudocode
We have shown that creating a curriculum this way has similar convergence properties to using a round robin instance rotation scheme. Specifically, it is possible to recover a round robin approach in the worst case and so SPaCE will converge whenever round robin does given that the performance threshold is kept flexible. Please see our paper for the full proof. Nevertheless, we expect and show first evidence that SPaCE outperforms round robin schemes by quite some margin.
Experimental Results
We show an excerpt of our experimental results applying SPaCE to robot navigation tasks. For a more thorough exploration of different benchmarks and further insights into SPaCE, please refer to the full paper.
The tasks we present here are contextual versions of the AntGoal and BallCatching environments. In AntGoal [Coumans and Bai, 2020], the agent has to navigate an Ant robot to a randomly sampled goal while in some instances one of its limbs is unresponsive. Contextual BallCatching [Klink et al, 2020] has the agent control a robot hand that has to catch a ball thrown from different distances and directions. For both of these tasks, we sampled each 100 training and test instances and compared the results of SPaCE and round robin training agents over 10 seeds.
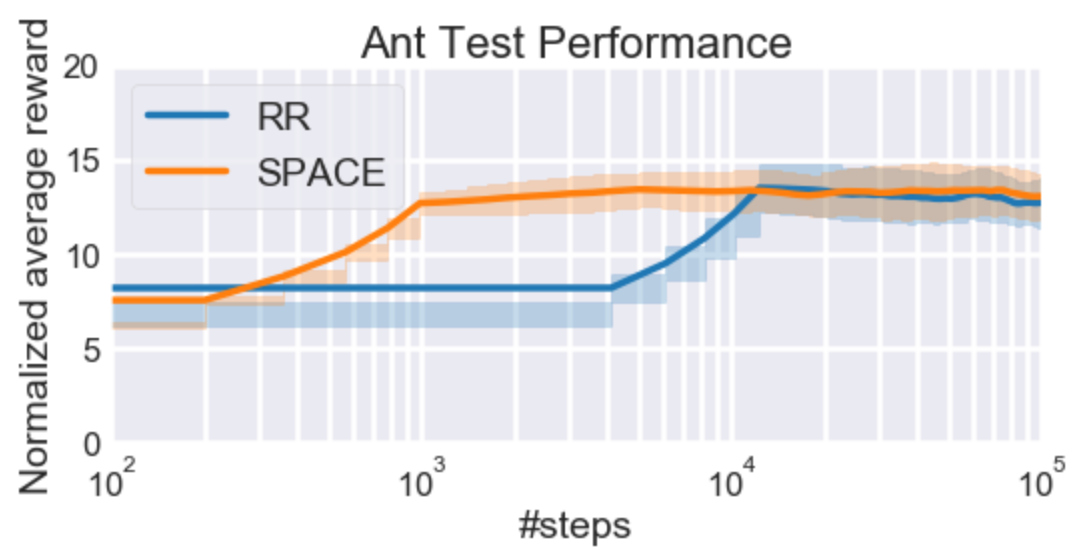

Figure 3: Results on the AntGoal and BallCatching environments over 10 seeds with standard deviation.
As we can see in Figure 3, SPaCE reached the final performance by over a factor of 10 quicker in both environments, making learning much more sample efficient compared to the naive round robin approach.
Conclusion
SPaCE provides a simple and general way to incorporate curriculum learning into contextual RL. Its success in our experiments shows that we can use curricula to facilitate generalization across instances and increase sample efficiency. We believe that this is a necessary step to make better use of RL in real-world applications like Dynamic Algorithm Configuration.
If you are interested in learning more about SPaCE, take a look at our ICML 2021 paper with extended insights and experiments.
References
[Matiisen et al., 2017] Matiisen, T., Oliver, A., Cohen, T. and Schulman,J. Teacher-student curriculum learning. CoRR,abs/1707.00183, 2017
[Fuks et al., 2019] Fuks, L., Awad, N., Hutter, F. and Lindauer, M. An Evolution Strategy with Progressive Episode Lengths for Playing Games. In Proceedings of the the 28th Joint Conference on Artificial Intelligence (IJCAI’19), 2019
[Zhang et al., 2020] Zhang, Y., Abbeel, P. and Pinto, L. Automatic curriculum learning through value disagreement. In Larochelle,H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS’20), 2020
[Wang et al., 2019] Wang, R., Lehman, J., Clune, J., and Stanley, K. O. POET: open-ended coevolution of environments and their optimized solutions. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO’19, 2019
[Klink et al., 2020] Klink, P., D’Eramo, C., Peters, J., and Pajarinen, J. Self-paced deep reinforcement learning. In Larochelle, H.,Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS’20), 2020
[Coumans and Bai, 2020] Coumans, E. and Bai, Y. Pybullet, a python module for physics simulation for games, robotics and machine learning. http://pybullet.org, 2020