By
Auto-PyTorch is a framework for automated deep learning (AutoDL) that uses BOHB as a backend to optimize the full deep learning pipeline, including data preprocessing, network training techniques and regularization methods. Auto-PyTorch is the successor of AutoNet which was one of the first frameworks to perform this joint optimization. Since training deep neural networks can be expensive, Auto-PyTorch follows a multi-fidelity optimization approach as supported by BOHB to achieve strong anytime performance. This means it first evaluates training pipelines on cheaper budgets, e.g. with few training epochs, and successively increases the budget using the knowledge from previous budgets to focus on strong pipelines in a parallel manner using a master-worker principle (see Figure 1). Auto-PyTorch then builds ensembles from these trained pipelines to further improve performance, also including traditional machine learning methods, such as gradient boosting or random forests, in these ensembles. To further improve early performance, Auto-PyTorch uses a similar approach to Auto-Sklearn 2.0 and samples the first configurations that are evaluated from a portfolio of configurations that have shown to perform well on test datasets.
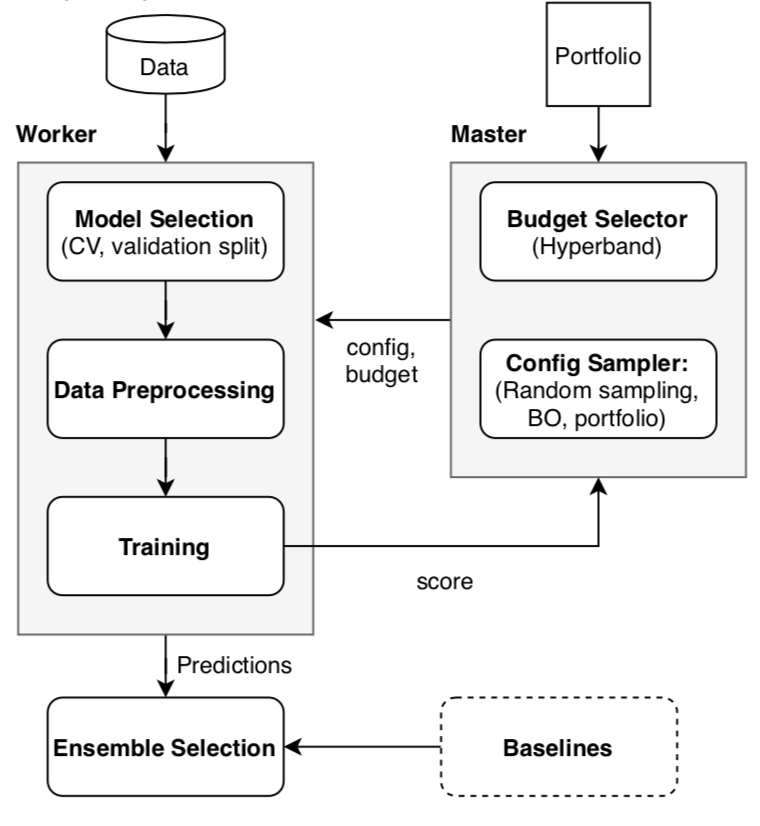
Figure 1: Components and pipeline of Auto-PyTorch based on a master-work principle.
To study the effectiveness of multi-fidelity optimization for the AutoDL problem, we performed numerous experiments on LCBench. LCBench is a dataset containing training logs of 2000 configurations on 35 datasets across different budgets, including learning curves for global and layer-wise statistics (e.g. validation accuracy and mean gradient at layer i) and serves as a learning curve benchmark. Figure 2 illustrates the performance of all these configurations across all datasets showing the mean accuracy on the validation set. We find that the performance distribution strongly varies across different tasks. However, there clearly are configurations which perform well across datasets which makes the transfer of well performing architectures via a portfolio to new tasks possible.
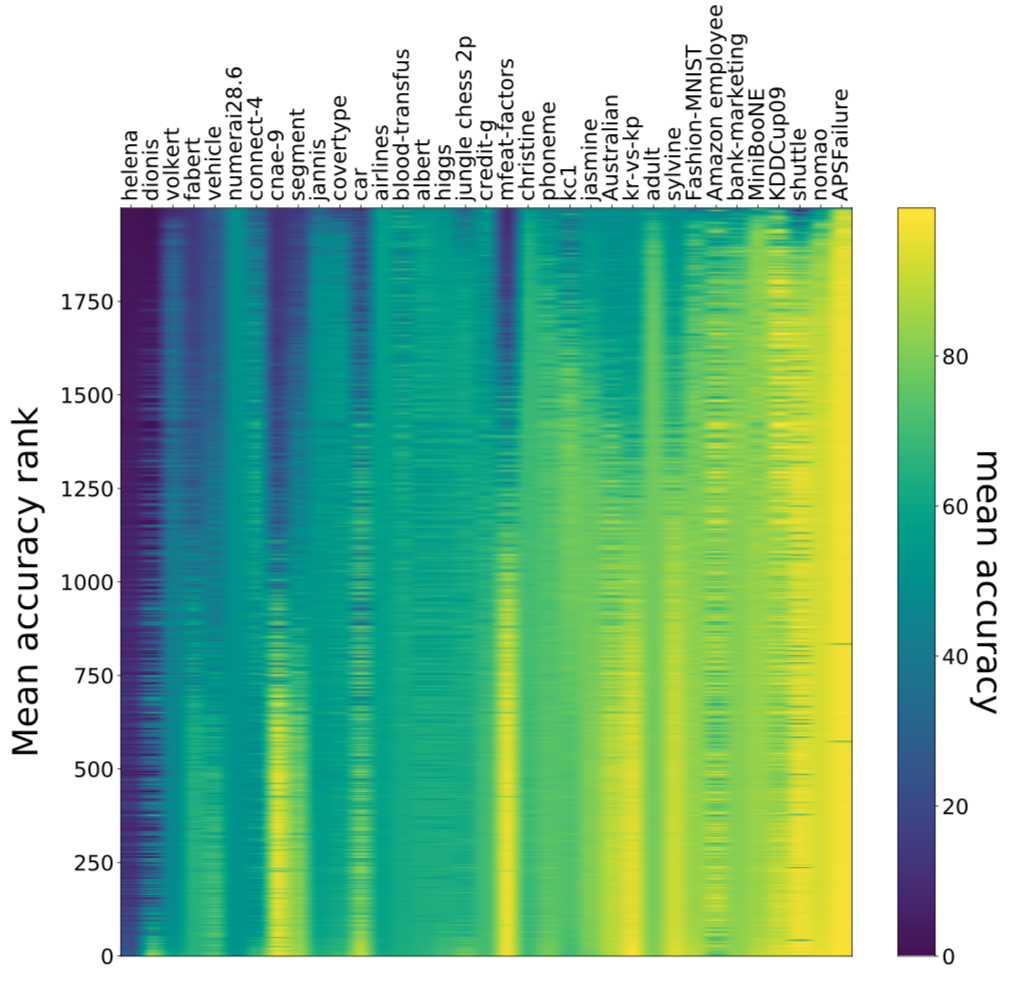
Figure 2: Mean validation accuracy of 2000 evaluated configurations across 35 datasets. For better visualization, we sort by mean accuracy/regret along each axis respectively.
We also use LCBench to study the importance of neural architecture and hyperparameters to investigate the importance of jointly optimizing neural architecture and training hyperparameters and how different budgets influence the importances. Figure 3 shows results of an fANOVA as well as a Local Hyperparameter Importance analysis on the data from LCBench at different budgets. We indeed find that both architectural parameters, like the number of layers in an MLP or ResNet, as well as training hyperparameters, like the learning rate, are highly important. Moreover, the importance of the parameters is very similar for different budgets.
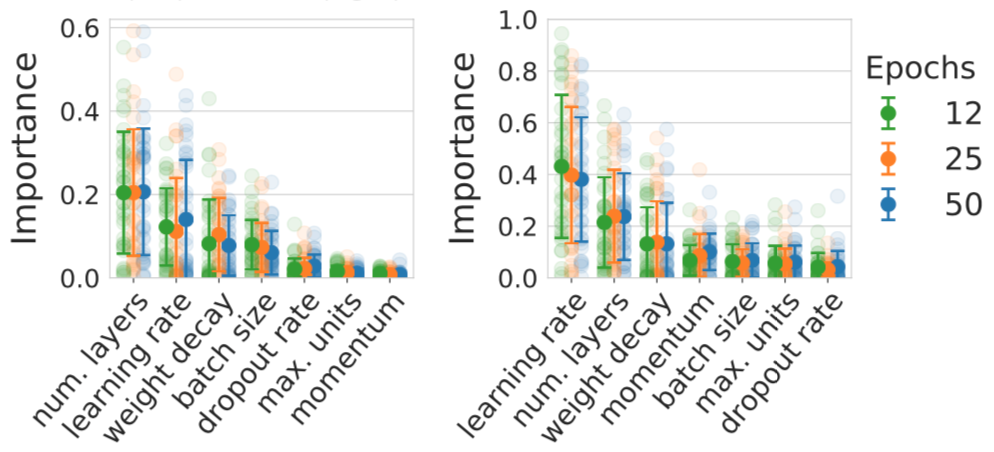
Figure 3: Hyperparameter importance according to fANOVA (left) and LPI (right) on LCBench.
Finally, we compared Auto-PyTorch to several state-of-the-art AutoML frameworks on different datasets from OpenML when running with the same computational budget for 1h (see Table 1). We find that Auto-PyTorch outperforms or performs equally well on all datasets.
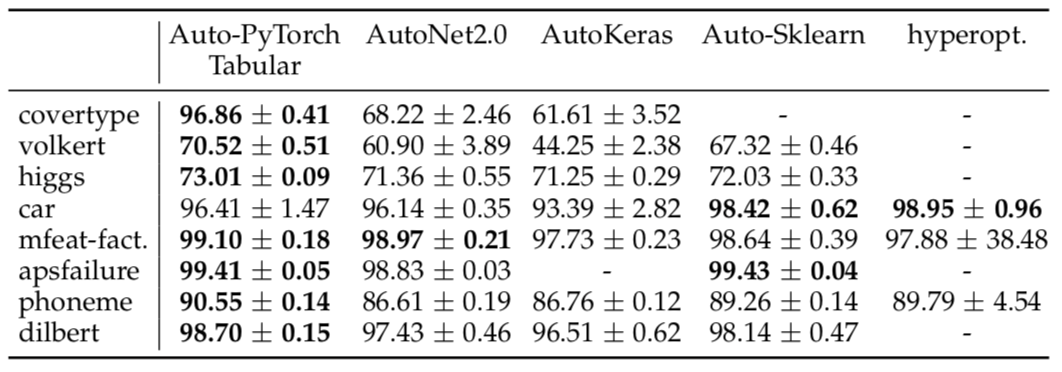
Table 1: Accuracy and standard deviation across 5 runs of different AutoML frameworks after 1h. ”-” indicates that the system crashed and did not return predictions.
Auto-PyTorch combines multi-fidelity optimization for AutoDL with configuration portfolios and ensembling to achieve strong performance. LCBench provides a dataset of learning curves for studying multi-fidelity optimization on different datasets. Both Auto-PyTorch and LCBench are publicly available. We also refer to the paper for further details and experiments.