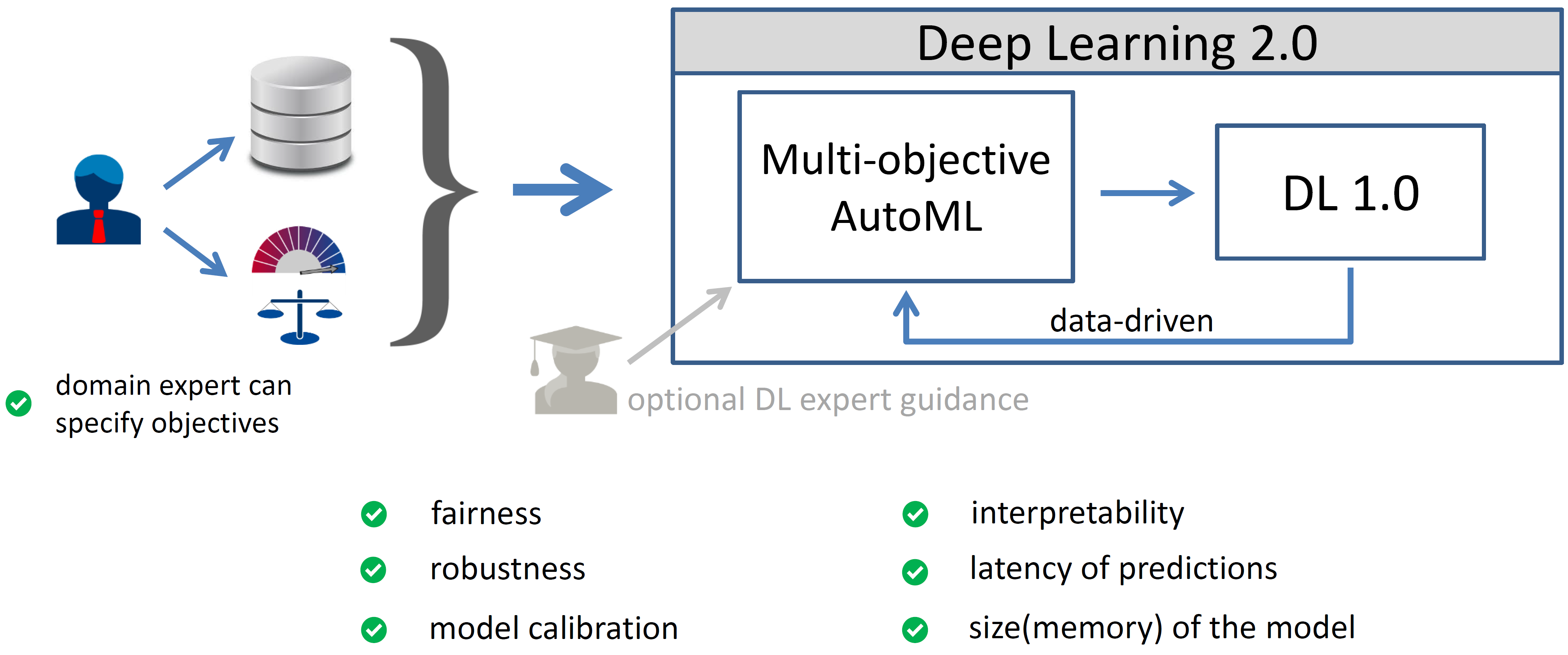
At the risk of sounding cliché, “with great power comes great responsibility.” While we don’t want to suggest that machine learning (ML) practitioners are superheroes, what was true for Spiderman is also true for those building predictive models – and even more so for those building AutoML tools. Only last year, the Netherlands Institute for […]
Can Fairness be Automated?
Posted on April 3, 2023 by Hilde Weerts, Florian Pfisterer, Matthias Feurer, Katharina Eggensperger, Eddie Bergman, Noor Awad, Mykola Pechenizkiy, Joaquin Vanschoren, Bernd Bischl, Frank Hutter