By
Our ML Freiburg lab is the world champion in automatic machine learning (AutoML) again! After winning the first international AutoML challenge (2015-2016), we also just won the second international AutoML challenge (2017-2018). Our system PoSH-Auto-sklearn outperformed all other 41 participating AutoML systems.

The team from left to right: Marius Lindauer, Frank Hutter, Matthias Feurer, Katharina Eggensperger and Stefan Falkner
What is AutoML and the scope of the competition?
We all know how tedious and error-prone it is to hand-design a machine learning pipeline, which includes preprocessing, selecting the right classifier and the hyperparameters at all stages. That’s why we do research on how to automate this entire process and put a lot of effort into providing robust tools that make our research results available for everyone.
We believe that an ideal AutoML system should use the available budget and training data to automatically construct a pipeline without additional human input as shown in this simplified figure:
 The ChaLearn team already organized two competitions for systematically comparing such AutoML systems. The first competition was held 2015-2016 and the second (2017-2018) finished recently. In this post, we want to share our insights and discuss our winning entries to both competitions.
The ChaLearn team already organized two competitions for systematically comparing such AutoML systems. The first competition was held 2015-2016 and the second (2017-2018) finished recently. In this post, we want to share our insights and discuss our winning entries to both competitions.
First AutoML challenge
The first competition consisted of five rounds of increasing difficulty, focussed on supervised learning with featurized data. Each round was split into an auto– and a tweakathon-phase and presented five new datasets from unknown domains. Much like a Kaggle competition, the tweakathon phase allowed participants to submit predictions for test data, without any restrictions on how they obtained those predictions. In contrast, the auto-phase evaluated true AutoML systems: these were presented with 5 completely new datasets (X_train and Y_train) and had to automatically learn a model and make predictions for their respective test sets (X_test) within strict time and memory constraints. In both phases the participants were ranked on each of the 5 datasets and the team with the best average rank won.
Here at ML Freiburg, this competition sparked the development of the AutoML tool Auto-sklearn, which we extended from round to round. Auto-sklearn automatically constructs machine learning pipelines based on suggestions by the Bayesian optimization (BO) method SMAC. We warm-started SMAC using meta-feature-based meta-learning and built an ensemble in a post-hoc fashion to achieve robust performance. The Auto-sklearn pipeline we used is shown below.

During the later phases, it became clear that training machine learning pipelines on the full training data was too slow for larger datasets. To tackle this problem, we introduced a manual strategy: running fast machine learning pipelines on subsets of the data before starting the principled, Bayesian optimization-based approach described above. As the later stages mainly consisted of large datasets, we believe that this strategy was vital to the success of Auto-sklearn. For the next challenge, we worked on also making this part of the pipeline more principled.
Second AutoML competition
The same procedure as last year? Well, no, not exactly. For the second AutoML competition, we aimed to reason about subsets of the data in a more principled fashion and also changed many other details. In the end, our effort paid off by winning the submission, but we also congratulate the other participants to their nice alternative solutions. If you want to read more about how other submissions work, SigOpt released a blogpost describing also the submission of the runner-up solution.
In a nutshell, our submission worked as follows: we built ensembles from pipelines found by Bayesian optimization, searching a small but mighty space, combined with successive halving and warmstarted with a static portfolio. We describe each of these elements in our AutoML workshop paper and give a high-level description here.
Successive Halving
In the previous challenge, we learnt that using data subsets is useful to quickly obtain reasonable performance and also to yield enough information about which models might work well on the full dataset. We based our new submission on successive halving, a bandit technique for allocating more resources to promising configurations in a principled manner. More precisely, successive halving works with budgets, which can for example be defined in terms of number of datapoints or iterations. After running all of a set of ML pipelines for a small budget, it drops the worse half of the pipelines and doubles the budget of the remaining pipelines. This halving of pipelines and doubling of budget is successively repeated until only a single pipeline is trained on the whole budget. Here, we show a visualization of this powerful method:

Recently, simple successive halving has been extended in Hyperband to hedge against choosing the minimum budget too low or too high by calling successive halving with different starting budgets. In an upcoming blogpost, we will describe how our team combined Hyperband with Bayesian optimization in a method called BOHB.
Considered Classifiers
Ideally, we want to search a large and diverse space of possible machine learning pipelines, but we restricted ourselves to use only models that can be trained iteratively, namely random forests, XGBoost and linear models trained with stochastic gradient descent. Because of the strong performance of support vector machines on smallish datasets we also added them using data subsets as the budget.
Portfolio
In the previous challenge, we used meta-features computed on the actual dataset to warmstart Bayesian optimization, but now the time restrictions were tougher and the datasets were larger, so we wanted to use all of the available time to evaluate configurations. Therefore, we selected a diverse set of configurations (ML pipelines), which we refer to as a portfolio, that “covers a broad range of datasets” just like a team with a diverse skill set can tackle a broad range of problems. We built this team of configurations by performing greedy submodular function maximization, which we depict in the following picture: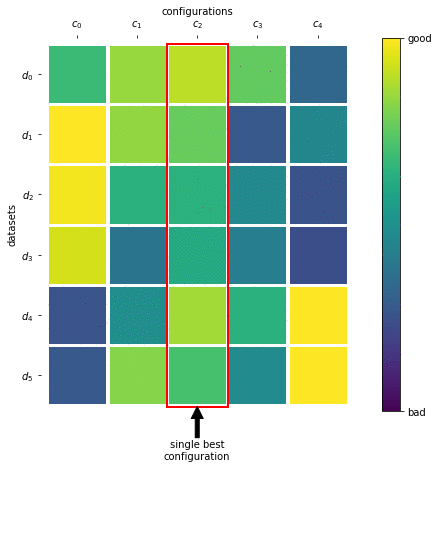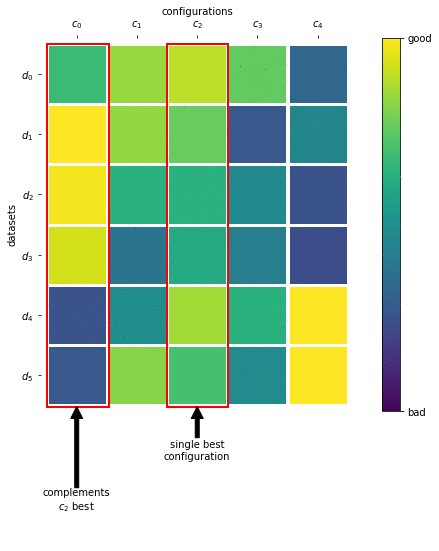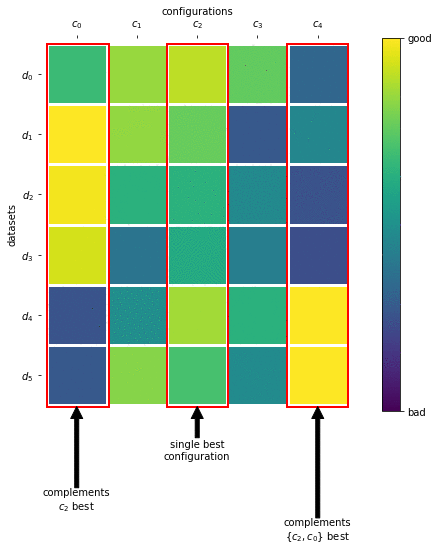
From the performance matrix we see that configuration c_2 performs best on average, so this is the first configuration we include in our portfolio. Next, we select c_0 as it provides the best joint performance together with c_2 compared to all other configurations, and iterate.
We built such a 421×421 performance matrix by running hyperparameter optimization on 421 datasets from OpenML and then running each of the 421 resulting configurations on all 421 datasets. We chose 16 of these 421 possible configurations to form our portfolio. Overall, starting off with a strong and versatile portfolio reduces the risk of wasting too much time on bad configurations; combining it with successive halving also allows to quickly identify well performing configurations.
Putting the pieces together
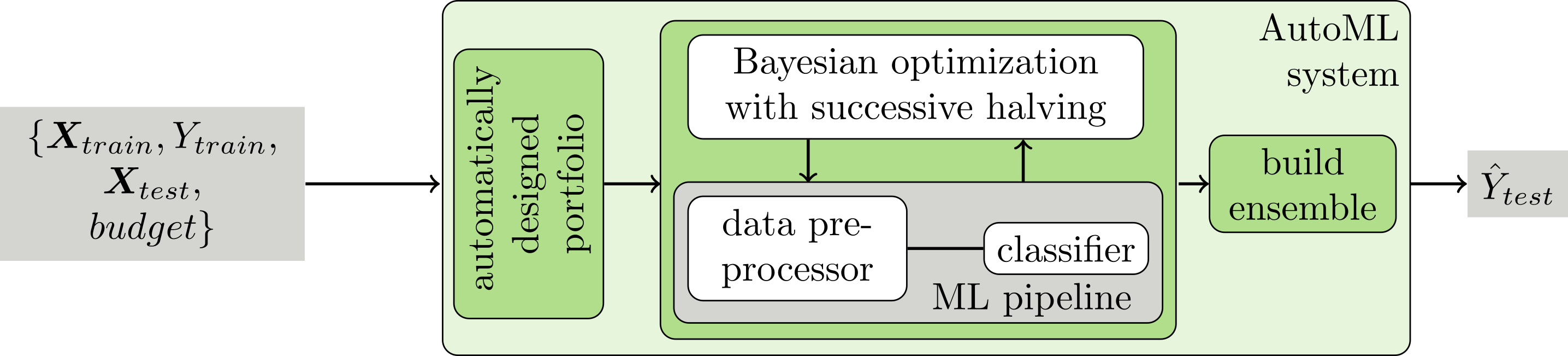
We put all these pieces together to form our submission. The following image depicts the AutoML system we used in the competition:
On each dataset, we first run one iteration of successive halving using our static portfolio. Then we iterate, using successive halving in combination with Bayesian optimization (where the first configurations are sampled at random until we have enough points to build a model).
Besides the scientific method, our submission also implements a strict resource management, robust error handling and underwent rigorous testing to ensure that our submission sticks to the given time (20 minutes per dataset) and memory (16 GB of RAM) limits and does not fail due to little things.
Concluding remarks
The second AutoML challenge posed a new interesting and fun challenge of applying machine learning without any human intervention. Of course, this blogpost only scratches the surface of the techniques employed in our submission; you can read about the rest in our AutoML workshop paper, in which we also analyze the results and performance of our submission.
Related material
- Our blogpost about the first challenge
- Our interview about the first challenge
- Blogpost by SigOpt about the 2nd AutoML challenge describing our solution and the solution from mlg.postech
- Auto-sklearn
- BOHB
- Link to the competition submission
- The competition’s hosts’ review of the first AutoML challenge
- The competition’s hosts’ introduction to the first challenge
- Codalab website of the challenge
- 4th Paradigm website of the challenge