Deep Learning (DL) has been able to revolutionize learning from raw data (images, text, speech, etc) by replacing domain-specific hand-crafted features with features that are jointly learned for the particular task at hand. In this blog post, I propose to take deep learning to the next level, by also jointly (meta-)learning other, currently hand-crafted, elements of the deep learning pipeline: neural architectures and their initializations, training pipelines and their hyperparameters, self-supervised learning pipelines, etc.
I dub this new research direction Deep Learning 2.0 (DL 2.0), since
- Like deep learning, it replaces previous hand-crafted solutions with learned solutions (but now on the meta-level),
- It allows for a qualitatively new level of automated customization to the task at hand, and
- It allows for automatically finding meta-level tradeoffs with the objectives specified by the user, such as algorithmic fairness, interpretability, calibration of uncertainty estimates, robustness, energy consumption, etc. It can thus achieve Trustworthy AI by design, breaking qualitatively new ground for deep learning.
From Standard Deep Learning to Deep Learning 2.0
Let me start by discussing why deep learning succeeded in the first place. Before deep learning, the traditional practice in machine learning was that a domain expert engineers features for the data at hand, and then one could use traditional machine learning methods, such as XGBoost (see the top of the figure below).
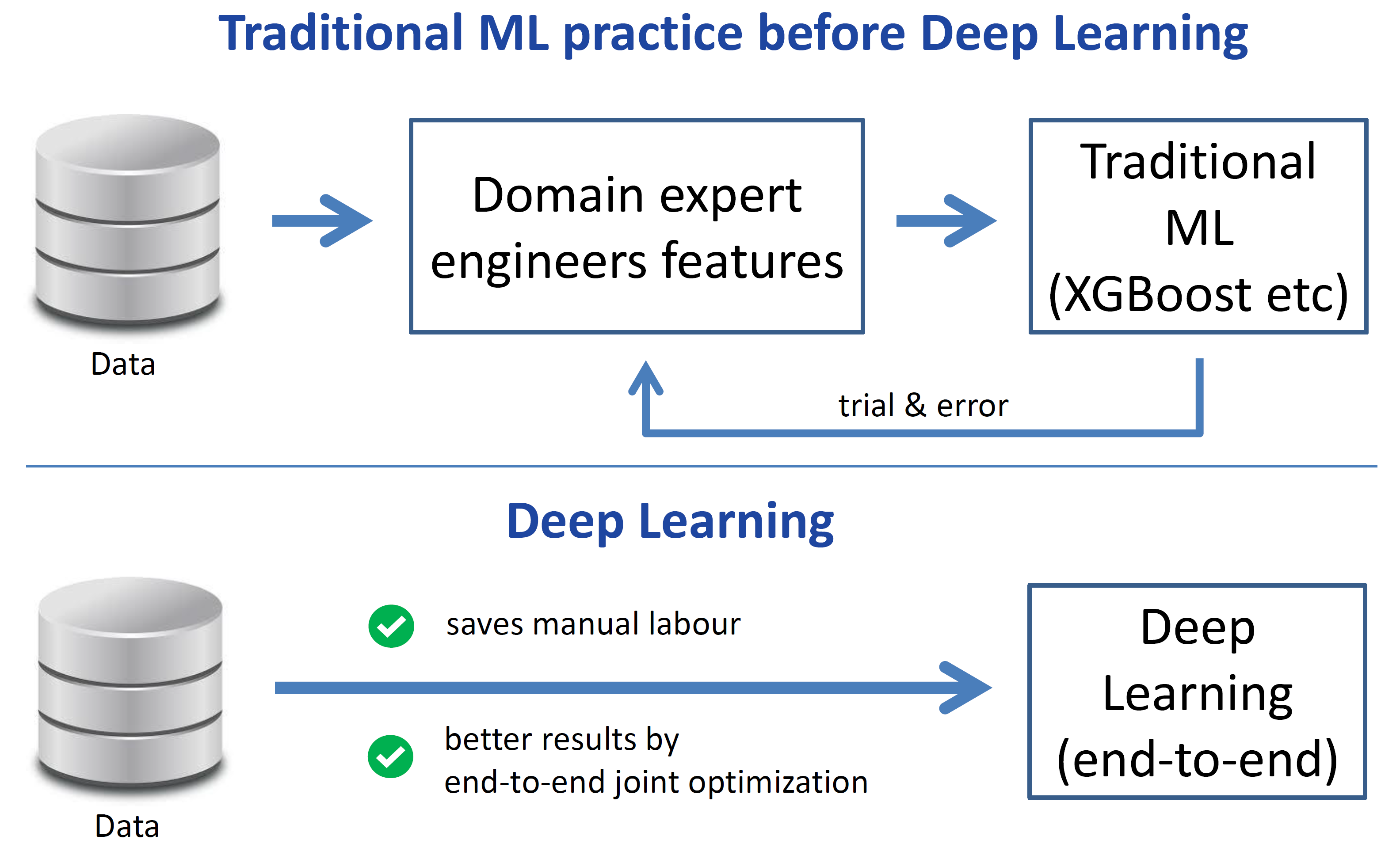
Feature engineering was often a slow and painful process, involving a lot of trial and error. Deep learning, in contrast, can learn features from the raw data, and can therefore completely bypass the manual feature engineering stage (see the bottom part of the figure above).
This saves manual labour and yields better results by an end-to-end joint optimization of the features and the classifier learned on those features. This success of deep learning is an example of the fact that throughout the history of AI, manually-created components have been replaced with better-performing automatically-generated ones [Clune, 2019, Sutton, 2019].
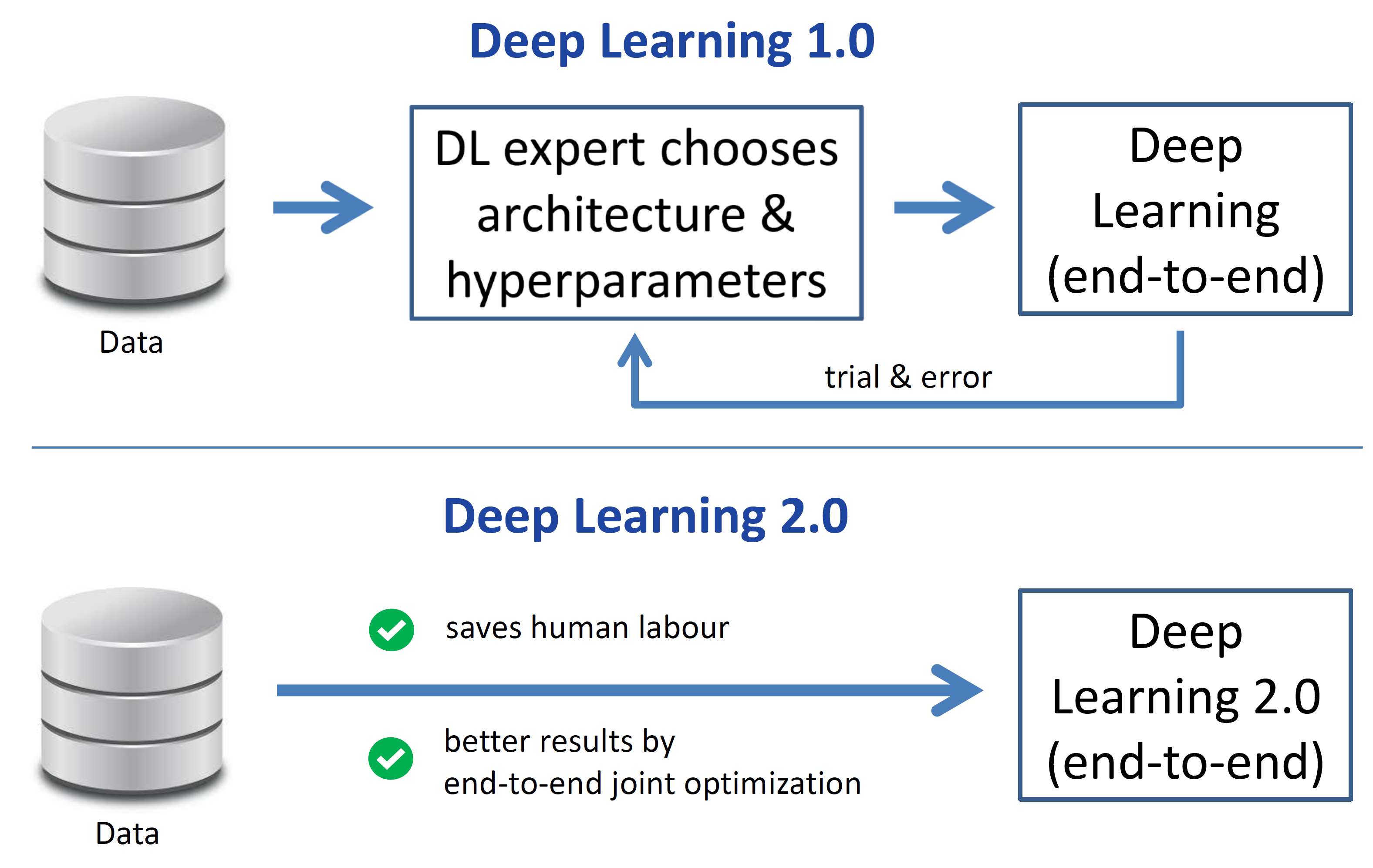
My proposal for Deep Learning 2.0 is to repeat this success on the meta-level. Deep learning has removed the need for manual feature engineering, but it has actually introduced the need for manual architecture and hyperparameter engineering by a DL expert. And like with feature engineering, this is a tedious trial & error process. To go from this state, which I call “Deep Learning 1.0” to Deep Learning 2.0, we again bypass this manual step, yielding the same advantages that deep learning brought over traditional machine learning. See the figure below for an illustration.
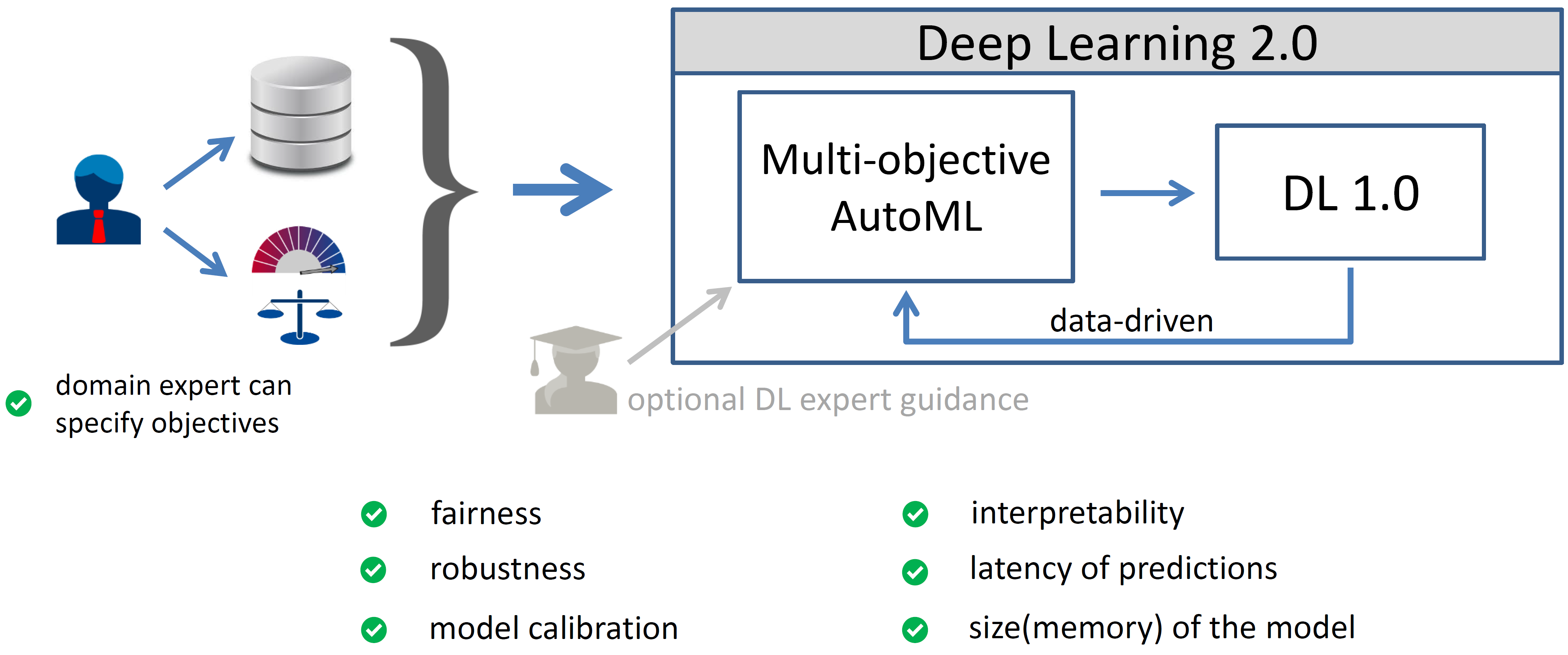
Deep Learning 2.0 can be realized by having an AutoML component that performs meta-level learning & optimization on top of a traditional base-level deep learning system. But this is not the complete picture of Deep Learning 2.0. In practice, we also often care about important additional objectives. That‘s why my vision for Deep Learning 2.0 includes that the domain expert can specify the objectives they care about in a particular application. For example, policy makers could specify the right algorithmic fairness criterion in a specific application, and then, what is now a multi-objective AutoML component can find instantiations of the base-level deep learning system that yield a Pareto front of non-dominated solutions. This then optimizes exactly for the users‘ objectives and can thus lead to trustworthy AI by design. Finally, I believe that Deep Learning 2.0 should also help DL experts by automating low-level tasks while accepting guidance by DL experts, allowing them to be more productive. See the figure below for an illustration.
The three pillars of Deep Learning 2.0
I currently see three pillars that need to come together to allow Deep Learning 2.0 to reach its full potential:
Pillar 1: Joint optimization of the deep learning pipeline
As mentioned above, the key to the success of deep learning was the automatic learning of features for raw data. Deep learning learns successively abstract representations of the raw data, with all of them optimized jointly in an end-to-end manner. The figure below gives an example from computer vision: prior to deep learning, researchers separately attacked the different levels of this feature learning pipeline in different isolated steps, with some people working on edge detectors, some people working on learning contours, some people working on combining contours to object parts, and finally some people working on object classification based on object parts. In contrast, deep learning optimizes all of these components jointly by optimizing the weights on all the connections in all of the layers to minimize a single loss function. Thereby, without being told to do so, deep learning learns edge detectors in the initial layers, in a way that lets them be combined well to learn contour detectors in higher layers, in a way that lets those be combined well to learn object parts in a way that allows a strong final classification. All end-to-end and jointly orchestrated.
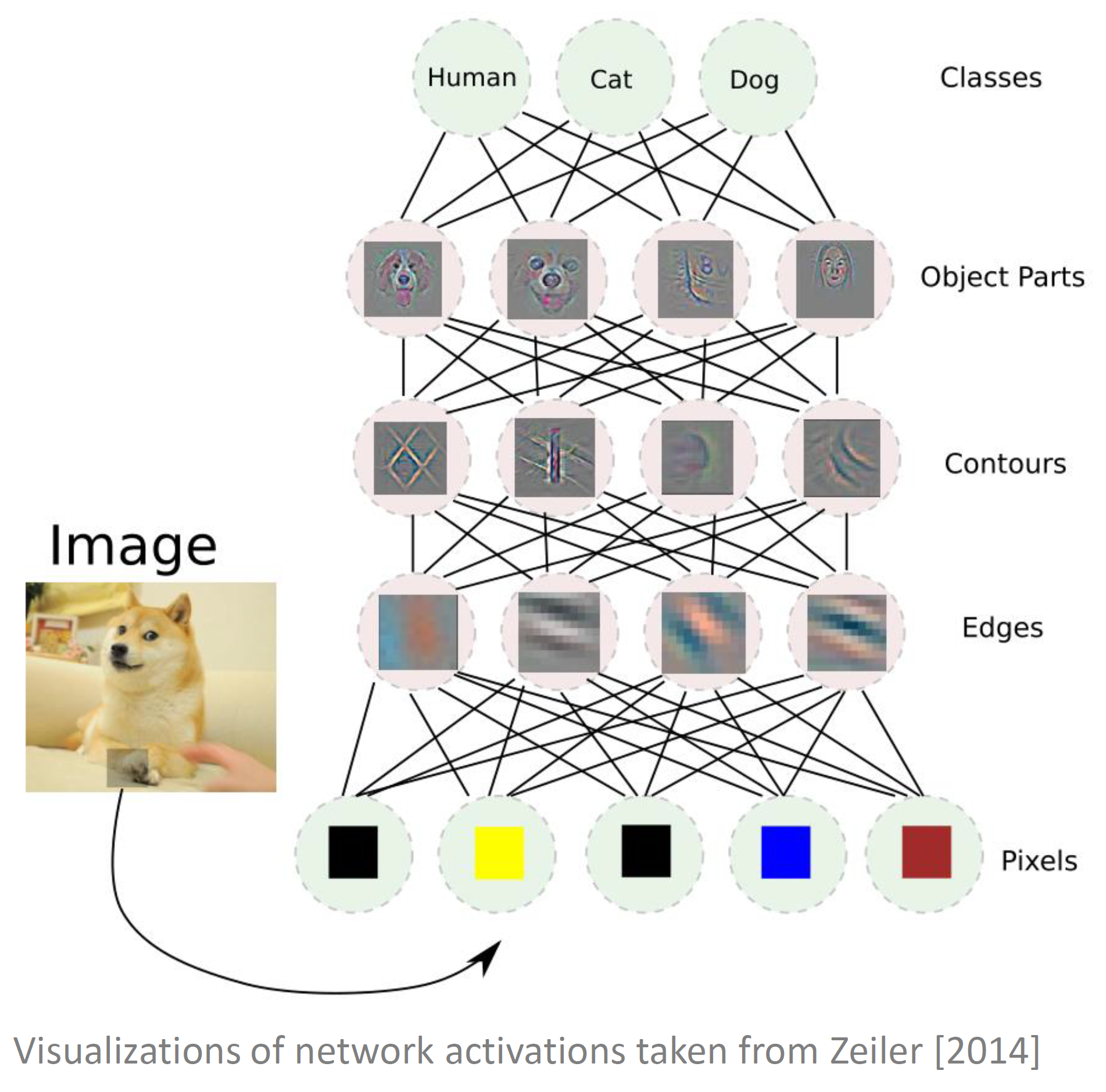
At the meta-level of deep learning, we currently have a similar situation as we had at the base level before deep learning: different researchers independently work on the various components of deep learning in isolation, such as architectures, weight optimizers, regularization techniques, self-supervised learning pipelines, hyperparameters, and so on. Deep Learning 2.0 proposes to jointly optimize these components, in a way that allows the inner deep learning to yield the best results.
Pillar 2: efficiency of the meta-optimization
Deep learning only became as successful as it is because the optimization of millions to billions of parameters can be efficiently solved by stochastic gradient descent (SGD). The success of Deep Learning 2.0 will thus depend to a large degree on the efficiency of the meta-level decisions. Researchers already routinely use hyperparameter sweeps or random search to improve empirical performance, but these will not suffice to effectively search the qualitatively new joint space of meta-level decisions.
The goal I personally set myself is to develop methods that only lead to a 3x-5x overhead over standard deep learning with fixed meta-level decisions. More sophisticated methods than grid and random search already exist, but they require substantial research efforts to reach this goal. The most promising methods fall into two categories:
- Gradient-based methods. There is already a lot of work on gradient-based neural architecture search, gradient-based learning of initial network weights, gradient-based hyperparameter optimization, and gradient-based learning of DL optimizers. These carry the promise to come with basically zero overhead, e.g., by alternating SGD steps on the meta-level and SGD steps on the base-level of the network weights. However, they are also very brittle, often with common catastrophic failure modes, and many research problems need to be solved for them to become similarly usable as robust off-the-shelf DL optimizers.
- Multi-fidelity optimization. Another promising approach is to extend sophisticated blackbox optimization methods, such as Bayesian optimization, with capabilities to reason across different approximations of the expensive cost function to optimize, similarly to Hyperband. Bayesian optimization (BO) and Hyperband (HB) have already been combined, yielding the effective and robust meta-level optimizer BOHB, but performance needs to be improved a lot more to reduce the overhead to 3x-5x evaluations of the expensive cost function.
Finally, tooling will need to be improved substantially, similar to the big push behind DL frameworks like Tensorflow and Pytorch, in order to make the use of sophisticated meta-level optimization second nature to DL researchers.
Pillar 3: direct alignment with user objectives, by means of multi-objective optimization
In contrast to standard deep learning, Deep Learning 2.0 proposes to put the human domain expert back into the picture, allowing them to specify their objectives. The DL 2.0 system can then automatically optimize for precisely these objectives and present a Pareto front of possible non-dominated solutions that the domain expert can choose from. These user objectives can, e.g., include any definition of algorithmic fairness that can be selected specifically for the situation at hand (realizing that “fairness” means something very different in one context than in another context). Someone of course needs to define which solution is better than another, but that person should not be some DL engineer tasked to implement the system, but it should be ethicists, policy makers, and the like, who provide the objectives to be optimized without having to know how exactly the system works, but who can audit the final solutions provided and select the best tradeoff for the situation at hand. I argue that this direct alignment of the objectives being optimized with the user objectives has the potential to yield Trustworthy AI by Design.
In order to further build trust, I believe that Deep Learning 2.0 should also output reports to explain what information was gathered during the automated search process, what the effect of different choices was, etc. In contrast to a manual tuning process by DL experts, Deep Learning 2.0 yields reproducible results, and these reports also make the process explainable and auditable. This will further increase trust in Deep Learning 2.0. and could also be directly used to comply with possible future legislation requiring explanations of how a model was selected.
Relationship to Other Trends in AI
Relationship to Foundation Models
A huge trend in deep learning is the use of large pretrained models (or so-called foundation models) that can be adapted for many downstream tasks. This trend has been here for vision models pretrained on ImageNet for almost a decade and has amplified with the rise of generative pretraining in natural language processing, e.g., with GPT-3. It is easy these days to download a pretrained model and fine-tune it to a target task, or, in the case of GPT-3, even use the model directly without any fine-tuning but with example data being specified in an appropriate prompt. This prevalence of pretrained models begs the question how DL 2.0 relates to these models.
The answer is twofold. Firstly, various aspects of what you do once you have a pretrained model can be seen as a DL 2.0 problem. Be it fine-tuning or prompt tuning, there are always knobs to be set. In fine-tuning, those include the entire training pipeline used in the fine-tuning phase (choice of optimizer, learning rate schedule, weight decay, data augmentation, and all kinds of other regularization hyperparameters). Likewise, prompt tuning introduces new choices on the meta-level, such as the prompt’s length and initialization, as well as possible ways of prompt ensembling.
Secondly, and more importantly, pretrained models don’t appear out of thin air. It requires careful choices of many different parts of the DL pipeline to obtain the best pretrained models, making this a prime Deep Learning 2.0 problem. This problem also directly features all three pillars of DL 2.0:
- Joint optimization of the entire DL pipeline. As in other areas of DL, there are many degrees of freedom that may have complex interactions: the neural architecture, the optimization and regularization pipeline, the SSL pipeline, and all of these components’ hyperparameters. With the exceedingly expensive training of current foundation models, even these individual components have not been comprehensively optimized, let alone their interactions; this leaves a lot of performance potential on the table.
- Efficiency. With training costs in the millions of dollars for individual models, efficiency is absolutely crucial even for the simplest of hyperparameter optimizations, and ever more so when trying to jointly optimize multiple components. Due to the high costs of training individual models, it is already common practice to tune hyperparameters on downscaled versions of the model / using cheaper training pipelines, and for some types of hyperparameters there are also parameterizations for which the optima remain stable across scales. Automated and principled techniques from multi-fidelity optimization would likely lead to further improvements, and gradient-based optimization is also very promising.
- Multi-objective optimization for achieving trustworthiness by design. Foundation models have a wide range of applications, and we aspire to train models that perform well across all of them, giving rise to a multi-objective optimization problem. Another clear multi-objective problem arises from avoiding models that are biased, racist, unfair w.r.t. one of many possible fairness metrics, etc. For example, the training data selection pipeline may be parameterized differently to retain high accuracy while also yielding high performance for these additional objectives. I believe this will be an important research direction in order to make foundation models more trustworthy by design.
Relationship to AI-Generating Agents
Jeff Clune has written a very compelling article on AI-Generating Algorithms (AI-GAs) [Clune, 2019], which I drew a lot of inspiration from, and the relationship to which I therefore discuss in a bit of detail. Jeff provides many examples of AI history in which manually-created components were ultimately replaced by better-performing automatically-created ones, and I fully agree with his conclusion that, in order to maximize expected progress, we ought to allocate more resources to research on the meta-level than we currently do. However, we differ in our emphasis on what problems to tackle on the meta-level. Jeff also proposes three pillars for AI-GAs, which inspired me to propose the three pillars for DL 2.0; however, these pillars are very different.
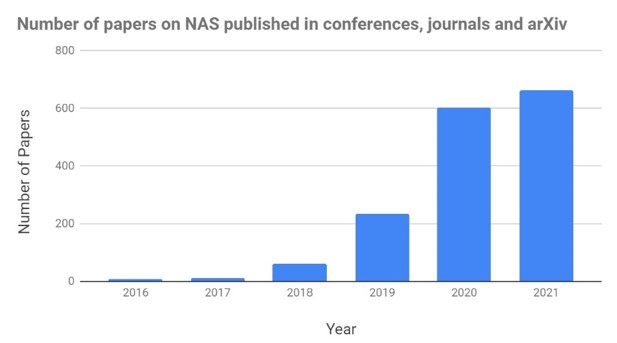
The first two pillars of Jeff’s AI-GAs focus on one individual piece of the DL pipeline each: (1) meta-learning architectures (i.e., neural architecture search), and (2) meta-learning the learning algorithms (learning optimizers & weight initializers like MAML). Both of these fields have already become extremely popular fields of research, with, e.g., over 1000 papers on NAS in the last two years (see the figure below); thus, despite the importance of these fields we no longer need to call on the community to intensify work on them. Rather, we should focus much more on their joint optimization, and also their joint optimization with SSL pipelines and with hyperparameters (a discussion of which is notably absent in Jeff’s AI-GAs [2019]). This joint optimization of the entire DL pipeline is my First Pillar of DL 2.0.
The Third Pillar of Jeff’s AI-GAs is on automatically generating effective learning environments. He breaks this down further into (1) the target-task approach and (2) the open-ended approach. The target-task sets a target (think: objective function) and tries to optimize for that, somewhat related to the joint optimization of the entire DL pipeline in my First Pillar, with a focus on curriculum learning. The open-ended approach focuses on creating strong AI via a co-evolution of learning environments and agents, similar to Darwinian evolution on Earth. While this is fascinating, the goals of DL 2.0 are much more down-to-Earth and closer to the target-task approach. DL 2.0 emphasizes efficiency (my Second Pillar, geared towards sustainability) and achieving trustworthy AI by design by getting the domain expert back into the picture and using multi-objective AutoML approaches (my Third Pillar). Neither of these crucial elements is part of the AI-GA vision, and both are under-researched and deserve much more attention by the DL community than they have received thus far.
Finally, I would like to remark that, in my eyes, DL 2.0 also substantially strengthens the basis for AI-GAs. The success of Jeff’s AI-GAs rests on the assumption that they outperform the “manual approach to AI”, but if AI-GAs require 10,000x longer than a single model run (as, e.g. early evolutionary NAS methods do), then I doubt that it will be competitive with human DL experts. In contrast, DL 2.0 emphasizes efficiency (my Second Pillar) and is well posed to make AI-GAs much faster and a much more competitive alternative to the manual approach.
Relationship to Human-level AI
Since Deep Learning 2.0 makes deep learning even more powerful, a natural question is how it relates to strong AI (aka artificial general intelligence, AGI – understanding or learning any task at human level). While I will not delve into the ethical question of whether we should try to attain strong AI, I believe that it is virtually impossible to attain strong AI without the AI being able to assess and improve its own performance. This self-assessment and self-improvement can take many shapes, but if the base-level AI consists of deep learning, then the multi-objective AutoML component in Deep Learning 2.0 is a very natural way to implement self-improvement. Summarized somewhat provocatively: “We will never succeed in constructing strong AI if we as humans need to manually tweak our method’s hyperparameters all the time.”
Strong AI is also the stated main objective of Jeff Clune’s AI-GAs [2019], and as discussed above, DL 2.0 will likely provide a boost to AI-GAs, thereby also implicitly helping a possible path towards strong AI. The same is true for DL 2.0’s potential role in improving foundation models. The focus on user objectives and multi-objective optimization in DL 2.0 also makes me hopeful that it will contribute tools towards constructing strong AI in a way that actually benefits humans along their complex and varied sets of objectives.
A frequent question somewhat related to strong AI is whether meta-level learning should stop at the meta-level, since several degrees of freedom are still left (e.g., the choice of search space). As humans, we have gotten away with the ability of learning and the ability of “learning to learn” (an increasingly popular subject in human learning), but we haven’t really needed the concept of “learning to learn to learn” so far. Similarly, in AutoML, we have witnessed methods to be more robust at the meta-level – e.g., we almost always use our hyperparameter optimizers with default hyperparameters (although it’s a fun fact that changing them can improve things to some degree, see, e.g., our paper on assessing the importance of BO’s hyperparameters or my PhD thesis’ Section 8.2 on “Self-Configuration of ParamILS”). The meta-meta-level might thus still be of interest, but I doubt that we’ll need to go much beyond it.
Deep Learning 2.0 is Long Underway
Deep Learning 2.0 builds on many components that have already been developed for many years. Meta-level optimization is clearly nothing new, and we can build on thousands of papers on hyperparameter optimization, meta-learning and NAS. While there is far less work on the joint optimization of multiple meta-level components (Pillar One), a few do already exist, such as Auto-Meta and MetaNAS (both of which jointly optimize the neural architecture and its initial weights), Auto-PyTorch and AutoHAS (which jointly optimize the neural architecture and its hyperparameters), SEARL (which jointly optimizes the neural architecture and hyperparameters of deep RL agents), and regularization cocktails (which jointly optimize over a dozen different regularization choices). With these works having demonstrated the benefit and feasibility of jointly optimizing several parts of the DL pipeline, I believe we will see many more works along these lines in the future.
Pillar Two on efficient meta-level optimization has already been researched extensively in the communities on hyperparameter optimization and NAS. Components that promise efficiency include transfer learning, online optimization, gradient-based optimization, multi-fidelity optimization, and the inclusion of human expert knowledge on the locality of the optimizer. With all these quite orthogonal directions in place, we have great foundations to succeed in achieving efficiency for Deep Learning 2.0.
Concerning Pillar Three, there is also a lot of existing work on multi-objective optimization that Deep Learning 2.0 can build on. With hardware-aware NAS being a major driver in NAS research, many NAS papers already tackle secondary objectives, such as latency, parameter count, and energy consumption of architectures. Furthermore, there are also already a few lines of work on hyperparameter optimization that address fairness as a secondary objective, and even though these haven’t been connected to deep learning yet I do not see any fundamental obstacles to this.
Based on this prior work, one could even argue that NAS is already starting to become the first instantiation of Deep Learning 2.0: we already have the beginnings of joint NAS+X (Pillar One), efficient gradient-based methods (Pillar Two) and multi-objective optimization (for limited objectives, Pillar Three). Of course, there is much left to be done on all of the pillars, but the existence of all of these puzzle pieces makes Deep Learning 2.0 very tangible and likely to succeed.
Deep Learning 2.0 is Destined to Succeed
I believe Deep Learning 2.0 is destined to succeed since it is desirable for all stakeholders: domain experts, DL experts, policy makers, and the industry.
DL 2.0 from a Domain Expert Perspective
While domain experts were an integral part of the traditional machine learning pipeline (since their domain knowledge was required to create and engineer strong domain-dependent features), this task has been taken over by deep learning. Domain experts thus cannot easily steer traditional deep learning systems anymore to actually yield models that they would trust. Deep Learning 2.0 finally returns this control back to the domain experts, by directly optimizing the objectives they specify. This allows domain experts to build trust and will lead to a greater acceptance of DL 2.0 than standard deep learning.
Furthermore, Deep Learning 2.0 allows even users without DL expertise to effectively use DL themselves, without blocking on rare and expensive DL experts. This greatly enhanced usability will allow DL 2.0 to become even a lot more pervasive than standard DL.
DL 2.0 from a DL Expert Perspective
DL experts still often apply manual search to optimize hyperparameters since existing automated methods for doing so, such as Bayesian optimization, (1) are too slow, (2) do not allow them to integrate their domain knowledge, and since manual search (3) allows them to build intuition about the problem at hand. However, nobody enjoys tuning hyperparameters, and DL experts would much prefer having their hyperparameters being optimized automatically. The same is true for architectural decisions, as well as choices of the optimization, regularization and SSL pipeline: if these could be set efficiently and automatically, DL experts would much prefer that, since that would clearly help them be more effective in their work. In contrast to the current state of affairs, Deep Learning 2.0 will (1) be efficient (see Pillar Two), (2) allow DL experts to integrate their knowledge (see, e.g., our work on guiding Bayesian optimization with expert-defined priors over the location of the optimum), and (3) provide reports to explain the information gathered during the automated search process to build intuition and trust in the system by DL experts. I therefore believe that DL experts will fully embrace DL 2.0 systems to help them with their daily work.
DL 2.0 from a Policy Maker’s Perspective
Since Deep Learning 2.0 directly aligns its optimization with the stated user objectives, and since it is fully reproducible and auditable (in contrast to the subjective manual decisions by a DL expert), I believe that DL 2.0 will be viewed very favourably by policy makers. In fact, at some point, legislation may require the process of arriving at a certain machine learning model to be explainable and auditable, and by means of its automated reports DL 2.0 systems will directly comply with this possible regulation. Phrased provocatively, at some point the law may require the use of Deep Learning 2.0 😉
DL 2.0 from an Industry Perspective
Deep Learning 2.0 will lead to a substantial increase of the already billion-dollar deep learning market. It is destined to succeed because
- DL 2.0 projects can be executed without a DL expert in the loop, saving human labour, time and money;
- DL 2.0 can yield better results than standard deep learning;
- DL 2.0 can directly incorporate guidance by DL experts;
- DL 2.0 reconciles many issues related to the trustworthiness of deep learning; and
- DL 2.0 will be even more pervasive than standard deep learning.
Take-aways
Deep Learning 2.0 is the natural next step for deep learning. It repeats the success that deep learning had with replacing a crucial manual step in machine learning with a better-performing automatic solution, but now works on the meta-level. It is of obvious appeal to industry since it will save time and money while yielding better results, it will democratize deep learning, it will make deep learning trustworthy by design, and it will be even more pervasive than standard deep learning.
Deep Learning 2.0 rests on three pillars: (1) joint optimization of the entire DL pipeline, (2) efficiency of that meta-optimization; and (3) direct alignment with user objectives, by means of multi-objective optimization. To maximize progress in the deep learning community, I strongly encourage the community to intensify work on these three pillars.