By
Much work in neural architecture search (NAS) is extremely compute hungry — so compute hungry that it hurts progress and scientific rigor in the community. When individual experiments require 800 GPUs for weeks nobody in academia can meaningfully join the community, and even in companies with huge compute resources nobody thinks of repeating their experiments many times in order to assess stability and statistical significance of results. Combine this with proprietary code bases and the whole thing looks pretty gloomy in terms of building an inclusive, open-minded yet rigorous scientific community.
To address this systemic problem, my lab teamed up with Google Brain to use their large-scale resources to create a NAS benchmark that makes future research on NAS dramatically cheaper, more reproducible, and more scientific. How? By evaluating a small cell search space exhaustively and saving the results to a table. The result, our NAS-Bench-101 benchmark, allows anyone to benchmark their own NAS algorithm on a laptop, in seconds: whenever that algorithm queries the performance of a cell, instead of training a neural network with that cell for hours on a GPU, we simply take a second to look up the result. Indeed, we evaluated 423k different architectures, with 3 repetitions each — and even with 4 different epoch budgets each in order to be able to benchmark multi-fidelity optimizers, such as Hyperband and BOHB. Of course, we made all of this data publicly available, and importantly, all the exact code for training the networks used for this data is also open-source.
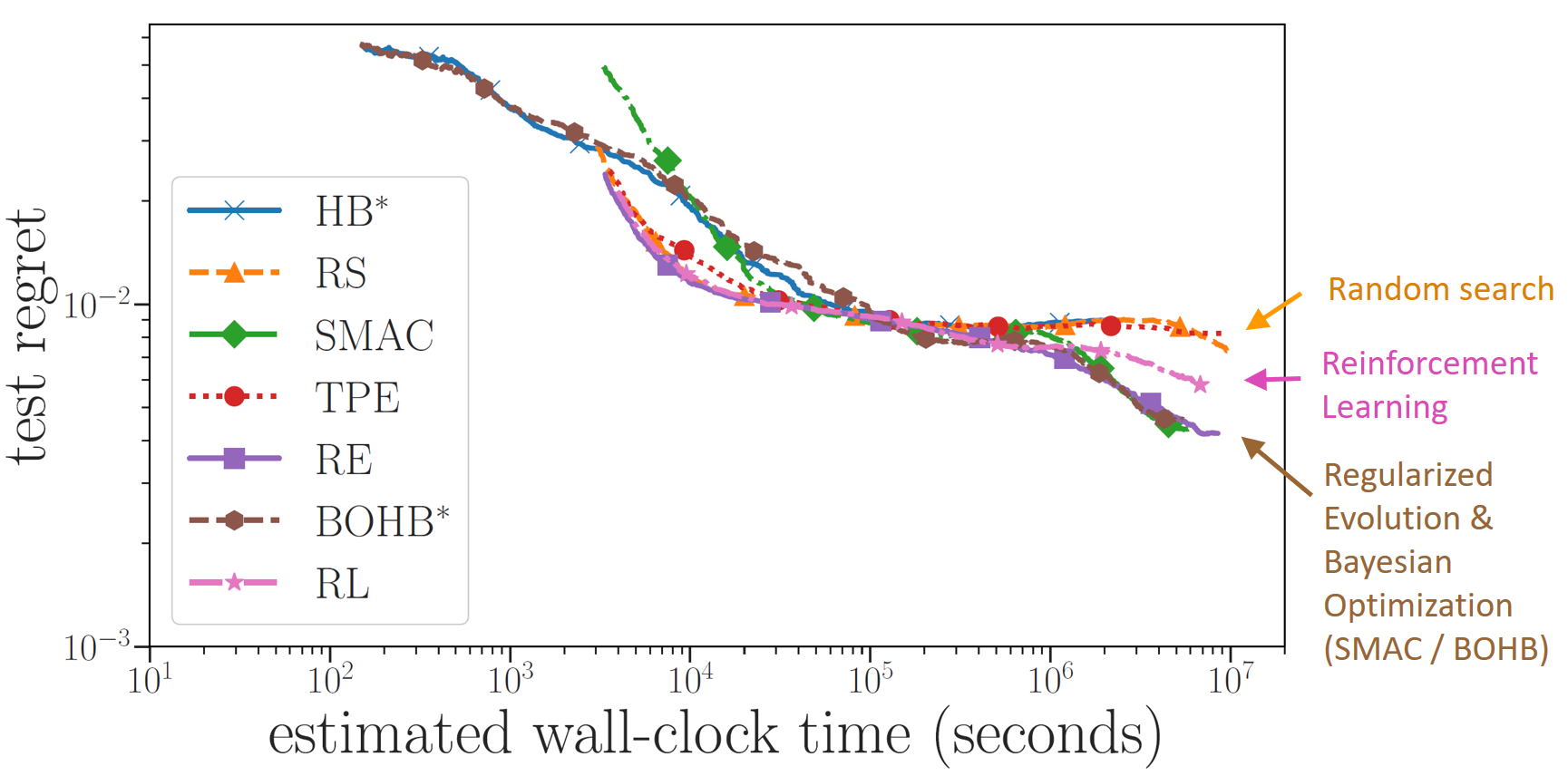
Figure 1: Evaluation of NAS & HPO algorithms on NAS-Bench-101. Note that on the right, reinforcement learning (RL) improves over random search (RS) and Hyperband (HB), but regularized evolution (RE) and the Bayesian optimization algorithms SMAC and BOHB perform better yet.
With this benchmark, we can trivially evaluate dozens of runs for a wide range of different NAS algorithms, see the figure above. We can also assess more classical hyperparameter optimization algorithms for NAS, in particular Bayesian optimization. One of the results we found is that reinforcement learning was better than random search, but both regularized evolution and Bayesian optimization (both SMAC and BOHB) were substantially better yet. Seeing that SMAC was published back in 2011, and that it was already used to win AutoML competitions with NAS in 2016, it may be surprising that the ICLR 2017 paper on NAS with RL did not compare to it, but there simply weren’t good benchmarks to do this easily and cheaply back then. Now that we have NAS-Bench-101, we can finally do such evaluations easily.
We’re glad to say that in the few months since we released NAS-Bench-101, it has been used by dozens of researchers, already more than amortizing the one-time cost of creating the benchmark. We hope that you will also consider using it! The data and Tensorflow code for the benchmark is available at https://github.com/google-research/nasbench and our scripts for the experiments in the paper are here: https://github.com/automl/nas_benchmarks. I am looking forward to more benchmarks of this kind, to ensure steady, quantifiable progress, and more rigorous experimentation in the field of NAS.
Many thanks to my PhD student Aaron Klein and our great co-authors from Google: Chris Ying, Esteban Real and Erik Christiansen and Kevin Murphy! For full details, check out the paper and Chris’ 5-minute oral at ICML 2019. Also see our blog posts on our other new NAS papers.