The Need for Realistic NAS Benchmarks
Neural Architecture Search (NAS) is a logical next step in representation learning as it removes human bias from architecture design, similar to deep learning removing human bias from feature engineering. As such, NAS has experienced rapid growth in recent years, leading to state-of-the-art performance on many tasks. However, empirical evaluations of NAS methods are still problematic. Different NAS papers often use different training pipelines, different search spaces, do not evaluate other methods under comparable settings or cannot afford enough runs for reporting statistical significance. NAS benchmarks attempt to resolve this issue by providing architecture performances on a full search space using a fixed training pipeline without requiring high computational costs.
The issue with previous NAS benchmarks (NAS-Bench-101, NAS-Bench-201, NAS-Bench-NLP), however, is that they are tabular benchmarks by nature, meaning that they provide a table that can be queried for an architecture’s performance, and they thus rely on a costly, exhaustive evaluation of all architectures in the search space. This in term leads to unrealistically small search spaces which causes significantly different behavior for NAS methods. As an example, NAS-Bench-201 merely contains 6466 unique architectures, leading to random search finding the optimum after only 3233 evaluations on average. In contrast, the most popular cell search space used by DARTS contains 10^18 architectures. In such a large space random search performes much worse. The question thus becomes: Can we design a NAS benchmark with low computational cost but featuring a large, more realistic, search space?
Surrogate Benchmarks
Surrogate benchmarks were first proposed by Eggensperger et al. (2015) to create benchmarks for hyperparameter optimization. They use a surrogate model trained on a dataset of architecture evaluations on a search space to predict the performance of any architecture and thereby can cover much larger search spaces. That being said, the next question is wether they can also yield predictions that are as accurate as the entries in a tabular benchmark. In the following, we show that this is not only possible but that surrogate benchmarks can be even more accurate.
The pivotal point that allows surrogate benchmarks to outperform tabular benchmarks lies in an issue of tabular benchmarks that has largely gone unnoticed. The stochasticity of mini-batch training is also reflected in the performance of an architecture i, hence making it a random variable Yi . Therefore, the table only contains results of a few draws yi ~ Yi (existing NAS benchmarks feature up to 3 runs per architecture). Given the variance in these evaluations, a tabular benchmark acts as a simple estimator that assumes independent random variables, and thus estimates the performance of an architecture based only on previous evaluations of the same architecture. From a machine learning perspective, knowing that similar architectures tend to yield similar performance, and that the variance of individual evaluations can be high, it is natural to assume that better estimators may exist. In fact, we show that surrogate benchmarks can provide better performance estimates than tabular benchmarks based on less data as it learns to smooth out the noise (Figure 1).
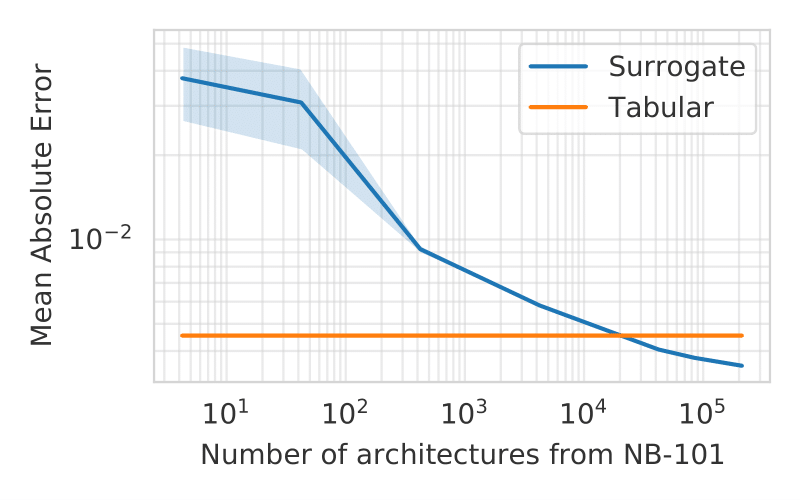
Figure 1: Performance of a tabular benchmark and a surrogate benchmark when trained on subsets from NAS-Bench-101. As ground truth, we used the mean of run 2 & 3 and used all available data as test set. The surrogate model is a Graph Isomorphism Network (GIN) trained on run 1. The tabular benchmark simply returns the table entry from run 1. The surrogate yields more accurate predictions even when trained on as few as 5 % of the available data.
NAS-Bench-301
We designed NAS-Bench-301 to cover the most popular NAS search space, as presented in the DARTS paper. By carefully sampling 60k architectures to evaluate we ensured that we achieve good coverage of the search space, particularly in well-performing regions that tend to be explored by NAS methods. We then selected the best performing surrogate models from a variety of candidates and trained them with the collected data to build surrogate benchmarks. Deep ensembles also allow us to improve the overall performance and to obtain predictive uncertainty. Running different optimizers on the true and surrogate benchmarks, we find that the trajectories on the surrogate closely resemble the true ones, but require a fraction of the cost (Figure 2).

Figure 2: Trajectories of different blackbox optimizers (BANANAS, Reguralized Evolution and Differential Evolution) on the true benchmark, a Graph Isomorphism Network (GIN) surrogate benchmark and an XGB surrogate benchmark.
Finally, we already used NAS-Bench-301 to drive NAS research. Previous research ran Local Search (LS) for 11.8 GPU days on the DARTS search space, concluding that it is not competitive with state-of-the-art NAS methods. We benchmarked LS on our surrogate benchmark and were able to reproduce these findings (Figure 3). However, due to the low cost of our approach, we were able to run for much longer. This revealed that LS in fact starts to drastically improve after the prior cutoff time, achieving strong performances. To validate this finding, we benchmarked LS on the true benchmark for >100 GPU days and obtain the same result. This allows us to revise the initial conclusion to: LS is also a state-of-the-art method on the DARTS search space, but only when given enough time.
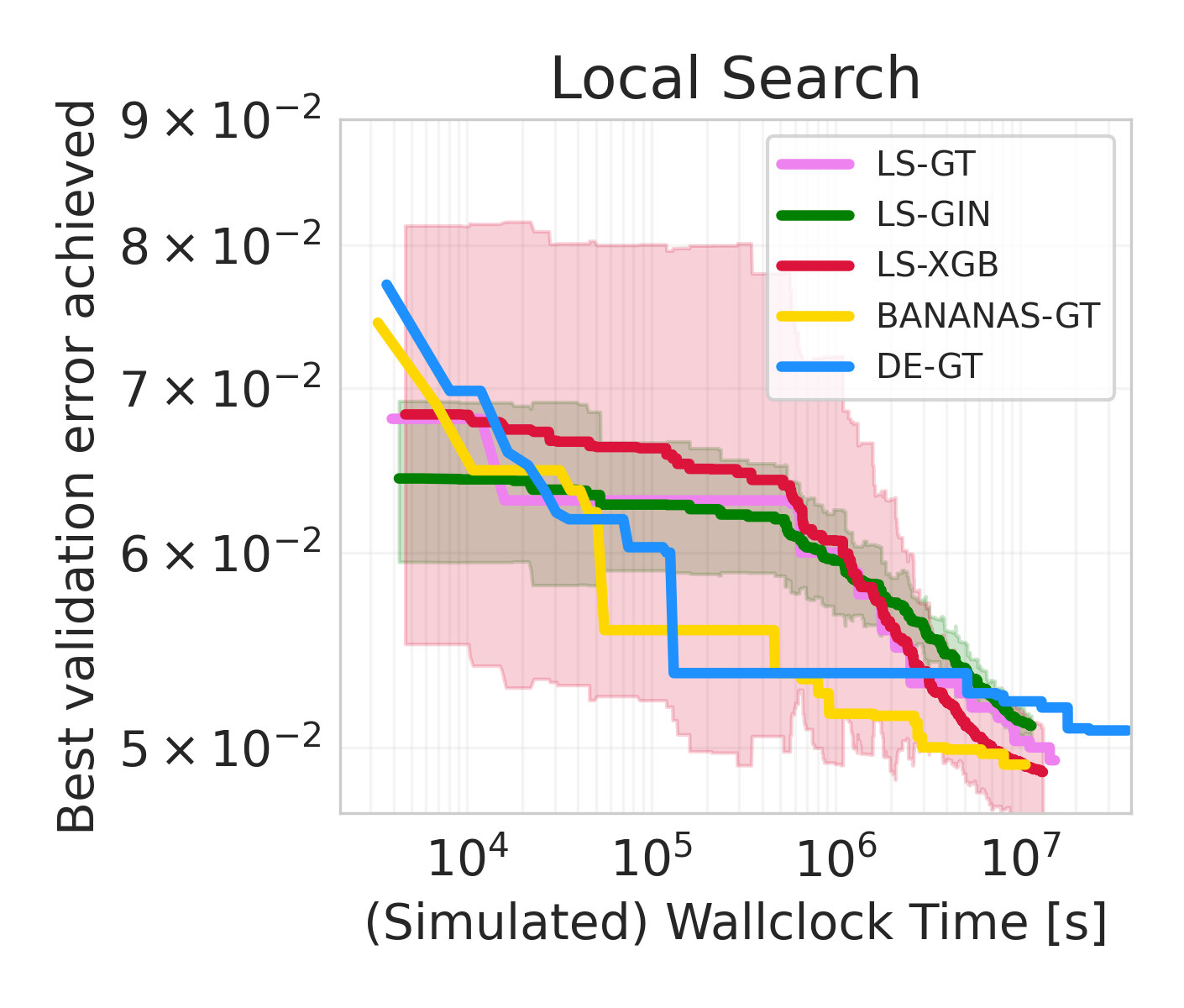
Figure 3: Local Search trajectories on the ground truth benchmark and our surrogate benchmarks. GT is the ground truth, GIN and XGB are results on NAS-Bench-301.
NAS-Bench-301 is the first surrogate NAS benchmark and first to cover a realistic search space, namely the one used by DARTS; orders of magnitude larger than all previous tabular NAS benchmarks. NAS-Bench-301 provides a cheap, yet realistic benchmark for prototyping novel NAS methods and allows fast benchmarking. Code for running NAS-Bench-301 is available at https://github.com/automl/nasbench301. We also refer to the paper for further details including guidelines on how to use NAS-Bench-301.