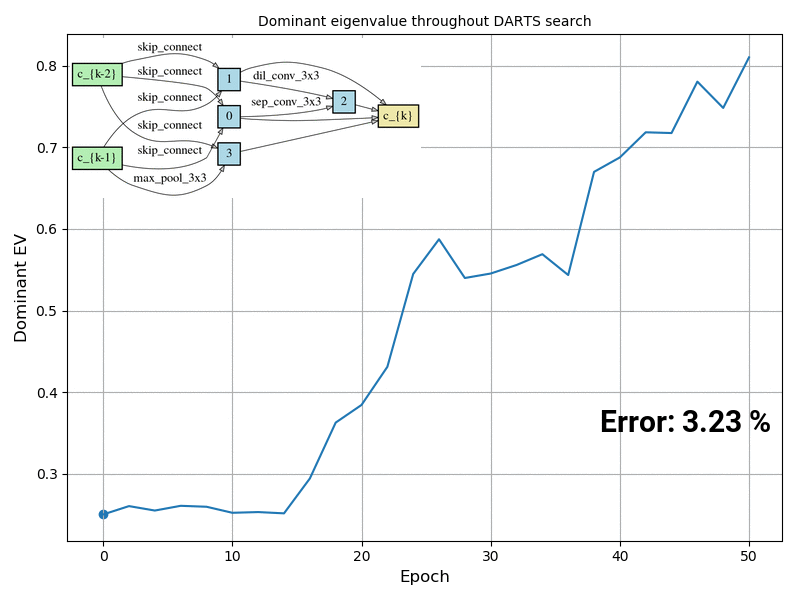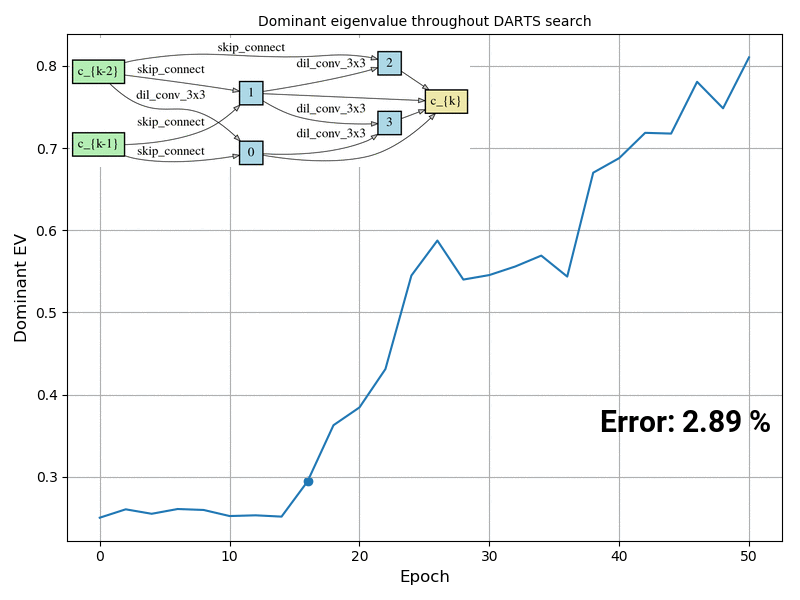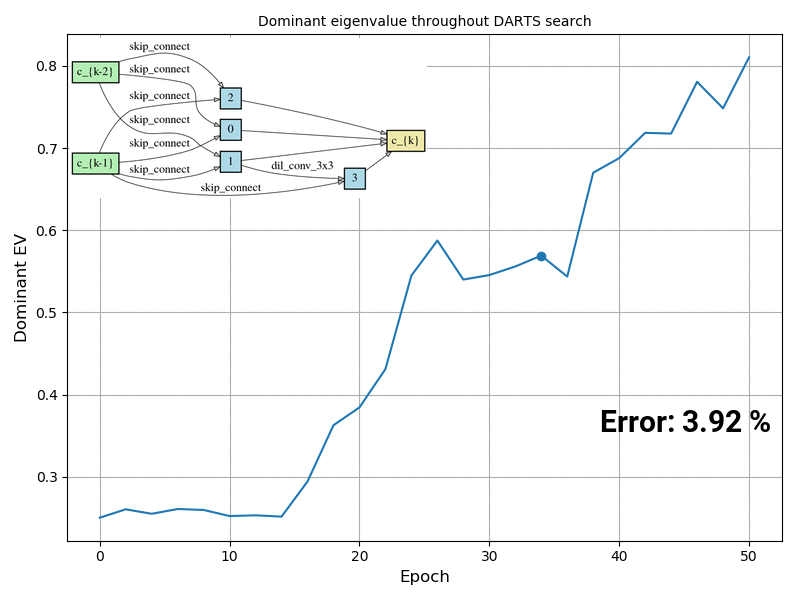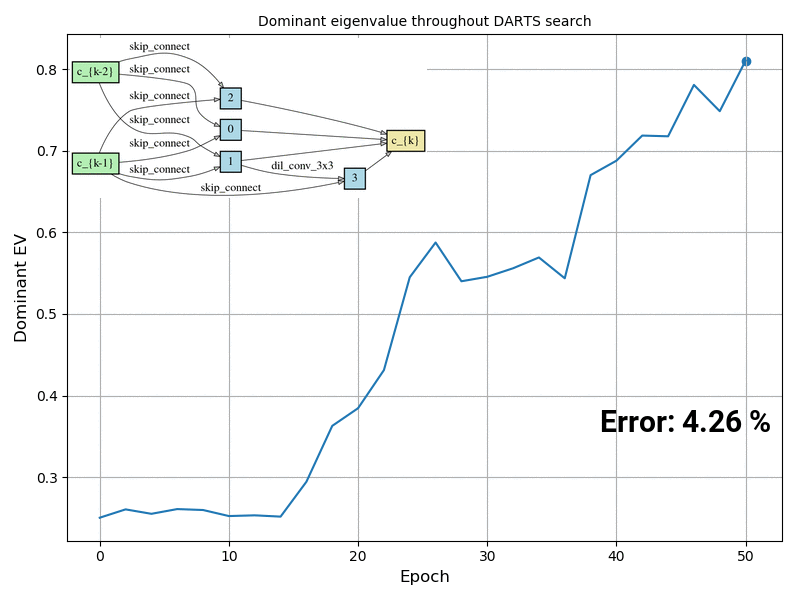
In many real world scenarios, deep learning models such as neural networks are deployed to make predictions on data coming from a shifted distribution (aka covariate shift) or out-of-distribution (OOD) data not at all represented in the training set. Examples include blurred or noisy images, unknown objects in images or videos, a new frequency band […]
Neural Ensemble Search for Uncertainty Estimation and Dataset Shift
Posted on December 1, 2020 by Arber Zela, Frank Hutter