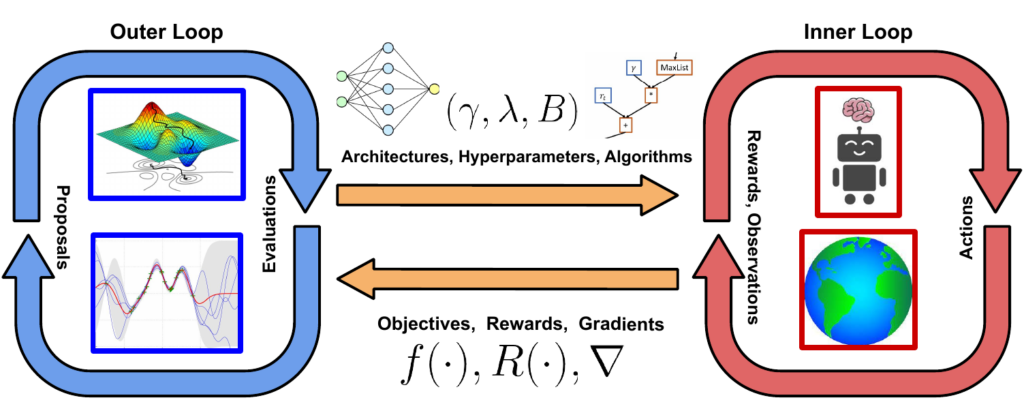
Reinforcement learning (RL) is a simple, yet powerful paradigm for training intelligent agents to perform a given task. To do so, RL agents interact with the world they exist in. Guided by a reward signal, RL agents learn in a trial-and-error fashion. That is, RL agents follow a policy, observe if the policy was good or bad and, depending on this outcome, update their policy to get better at a given task.
The simplicity of this paradigm raises the expectations that RL should be applicable in a wide variety of problem domains. However, in practice, it is well known that existing RL algorithms are brittle, require attention to minute implementation details and are sensitive to the experimental setup in general. As a result, RL has not found wide-spread adoption for many real-world tasks. AutoML provides ample solution approaches to overcome these issues in RL, but conversely, RL also offers novel opportunities for AutoML researchers.
Our groups have been at the forefront of research in the nascent AutoRL community since the field began. We provide a brief overview of the challenges and parts of the AutoRL pipeline based on the survey that we jointly authored.
We have various further resources available for the motivated reader and for the motivated researcher looking to get hands-on. Our work on analysing the importance of various hyperparameters of the AutoRL pipeline in model-based RL (MBRL) led to various important insights on the need to tune hyperparameters for MBRL and the case for dynamic tuning. While MBRL is already sample efficient, improving the sample efficiency of model-free RL (MFRL) needs a lot of work still to be done. We tackle some aspects of this while improving the dynamic hyperparameter tuning approach of population based training (PBT) in our work, SEARL. Our work on AutoRL in MFRL has also resulted in achieving state-of-the-art performance in RNA protein folding. We discuss all of these works in our blogpost:
We are interested in automating all parts of the AutoRL pipeline and would be very happy if motivated readers would like to reach out to us. See also our full list blog posts for our current work in AutoRL:
- Contextualize Me – The Case for Context in Reinforcement Learning
- Hyperparameter Tuning in Reinforcement Learning is Easy, Actually
- Understanding AutoRL Hyperparameter Landscapes
- Learning Synthetic Environments and Reward Networks for Reinforcement Learning
- CARL: A benchmark to study generalization in Reinforcement Learning
- Self-Paced Context Evaluation for Contextual Reinforcement Learning
- AutoRL: AutoML for RL
- Automatic Reinforcement Learning for Molecular Design